Scaling Hathora to 1 million CCU with Frost Giant


Launch day for a hit online multiplayer game doesn’t have an equivalent in any other industry. The genre's social nature increases the potential to go viral, so gamers around the world will all want to play at the same time. This puts significant strain on backend infrastructure, which studios must be prepared to handle seamlessly from day one.
The biggest game studios (Riot, Blizzard, Valve, Epic, etc) have collectively invested billions in building specialized solutions to this problem, but other studios can’t access these systems and must attempt to build them from scratch. The last thing you want is for your players' first experience to be one of frustration.
At Hathora, our expertise is in building scalable infrastructure, and our aim is to democratize server infrastructure for gaming studios via our server orchestration platform. We handle deploying and running headless game server instances across bare metal and cloud machines all over the world.
Our highest priority is to ensure that our product works flawlessly for our customers on their launch day, and we know from experience that there's no substitute for load testing when it comes to building confidence in a system. We spent these last few months designing and running a large scale load test to ensure the reliability of our platform, and we're pleased to share the methodology, learnings, and final results in this post.
How we did it
We wanted this test to be as realistic as possible, which effectively meant we needed to use a real game. Frost Giant Studios, one of our earliest customers, agreed to let us use their upcoming game, Stormgate, as the medium for our test. This had the added benefit of proving to them that Hathora will be able to handle the load if their game becomes massively popular.

Stormgate follows in the footsteps of the Warcraft and StarCraft series. External playtests have received exceedingly positive feedback, so we fully expect Stormgate to become a hit when it launches upon release.
The game is an immersive RTS set in a richly detailed universe where players build armies and engage in epic conflicts, blending elements of high-fantasy and futuristic technology.
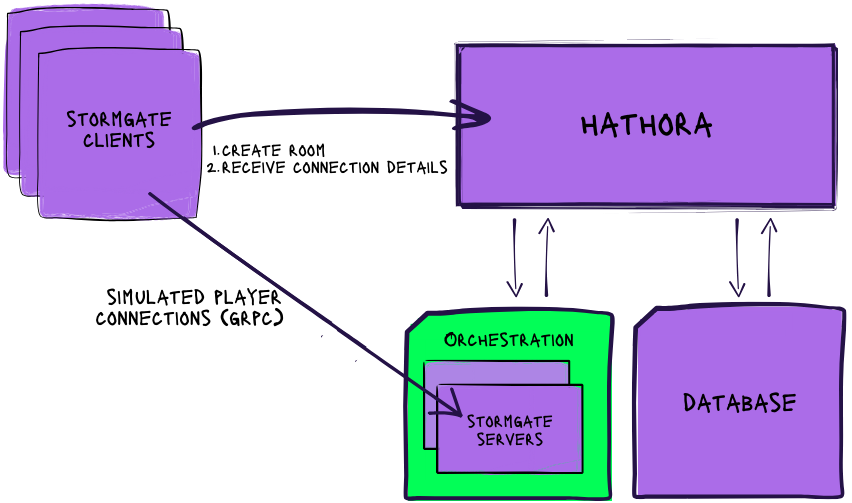
Architecture
We wanted to make sure that we would be able to handle a huge success on launch day, so we settled on 1 million concurrently connected users (1M CCU) as our load target.
The Stormgate game server was already running on Hathora, and Frost Giant provided us with a headless client that replays recordings of actual games and sends the traffic to the server. We modeled 2 players per game to simulate their 1v1 mode.
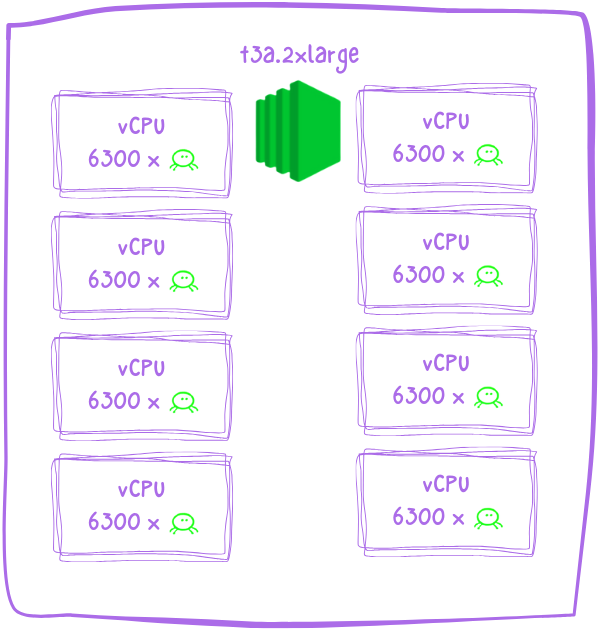
We chose to run the client test harness on EC2, and our partners at AWS graciously sponsored the compute required for this test. We created automation to spin up cloud instances on demand with the requisite scripts, dependencies, and environment variables preinstalled. Each EC2 instance was able to simulate about 6,300 players per vCPU.
Our simulated clients took the same actions as real game clients:
- Create a room.
- Query the host and port for the room.
- Open up two tcp connections to the room to simulate players and run a replay of a Stormgate playthrough.
The rate at which we created new rooms influenced both the duration of the test and the load it would put on our systems. In consultation with Frost Giant, we chose a rate of 30 new matches per second, or ~100k matches per hour.

We broke the project up into 3 concrete milestones: 10k, 100k, and finally 1 million CCU.
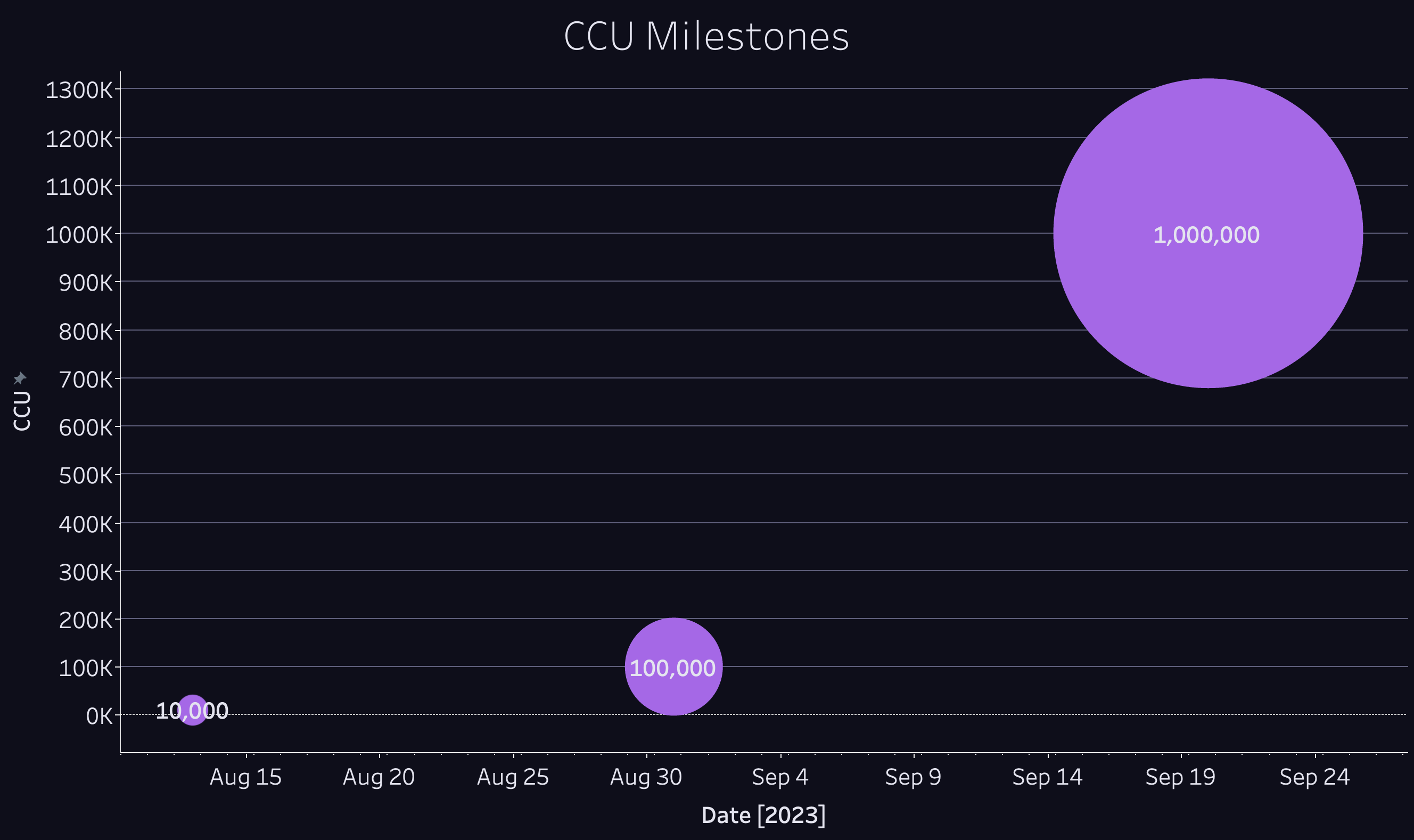
Disclaimer: Modern multiplayer games require an extensive suite of services like for identity, matchmaking, leaderboards, etc, but we only tested the Stormgate server and the orchestration layer since that's the service we provide.
Results
At each phase of the test, we initially encountered bottlenecks in our systems, some of which we anticipated and some of which surprised us. What follows is a summary of the challenges we encountered in attempting to hit each milestone, and how we ultimately overcame them to achieve 1M CCU.
10k CCU
- Problem: Too many database queries maxed out CPU on our API server
- Solution: We optimized our queries and scaled the API server horizontally
Within minutes of starting our 10k CCU test, we saw the CPU on our API server spike to 100%. Our API server became unresponsive and requests started timing out.
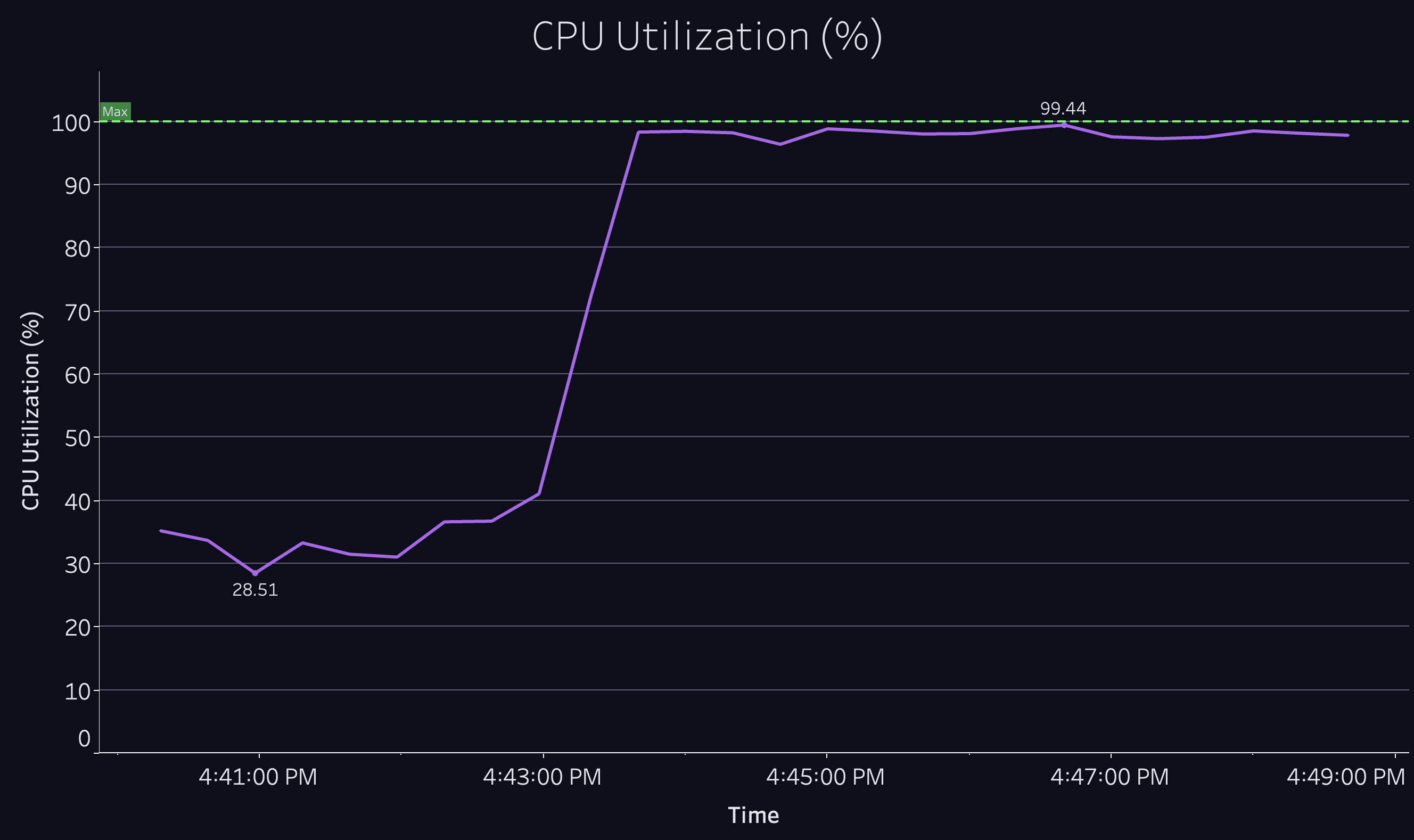
No obvious culprit for the CPU exhaustion stood out to us, so we hooked up a profiler to determine where the processor was spending most of its time:
| Ticks | Parent | Name |
|---|---|---|
| 252034 | 61.9% |
t node::fs::FSReqPromise
|
| 22106 | 8.8% |
t node::fs::FSReqPromise
|
| 2705 | 12.2% | LazyCompile: *processTicksAndRejections node:internal/process/task_queues:67:35 |
| 2355 | 10.7% | LazyCompile: *deserializeObject ~/hathora-server/node_modules/db/lib/db.cjs:2541:27 |
| 1926 | 81.8% | LazyCompile: *deserializeObject ~/hathora-server/node_modules/db/lib/db.cjs:2541:27 |
| 1564 | 81.2% | LazyCompile: *deserializeObject ~/hathora-server/node_modules/db/lib/db.cjs:2541:27 |
| 1467 | 93.8% | LazyCompile: *deserializeObject ~/hathora-server/node_modules/db/lib/db.cjs:2541:27 |
| 97 | 6.2% | LazyCompile: *parse ~/hathora-server/node_modules/db/lib/cmap/commands.js:431:10 |
| 361 | 18.7% | LazyCompile: *parse ~/hathora-server/node_modules/db/lib/cmap/commands.js:431:10 |
| 360 | 99.7% | LazyCompile: *onMessage ~/hathora-server/node_modules/db/lib/cmap/connection.js:130:14 |
| 428 | 18.2% | LazyCompile: *parse ~/hathora-server/node_modules/db/lib/cmap/commands.js:431:10 |
| 425 | 99.3% | LazyCompile: *onMessage ~/hathora-server/node_modules/db/lib/cmap/connection.js:130:14 |
| 423 | 99.5% | LazyCompile: * |
| 1754 | 7.9% | t node::fs::FSReqPromise |
| 1145 | 65.3% | LazyCompile: *processTicksAndRejections node:internal/process/task_queues:67:35 |
| 86 | 4.9% | LazyCompile: *stringifyFnReplacer ~/hathora-server/node_modules/safe-stable-stringify/index.js:230:32 |
| 85 | 98.8% | LazyCompile: *Transform._read ~/hathora-server/node_modules/winston/node_modules/readable-stream/lib/_stream_transform.js:161:38 |
| 85 | 100.0% | LazyCompile: *Writable.write ~/hathora-server/node_modules/winston/node_modules/readable-stream/lib/_stream_writable.js:286:37 |
| 1 | 1.2% | Function: ^stringify ~/hathora-server/node_modules/safe-stable-stringify/index.js:646:22 |
| 1 | 100.0% | Function: ^ |
| 85 | 4.8% | LazyCompile: *selectServer ~/hathora-server/node_modules/db/lib/sdam/topology.js:239:17 |
| 85 | 100.0% | LazyCompile: * |
| 85 | 100.0% | LazyCompile: * |
| 73 | 4.2% | LazyCompile: *serializeInto ~/hathora-server/node_modules/db/lib/db.cjs:3352:23 |
| 58 | 79.5% | LazyCompile: *serializeInto ~/hathora-server/node_modules/db/lib/db.cjs:3352:23 |
| 49 | 84.5% | LazyCompile: *serialize ~/hathora-server/node_modules/db/lib/db.cjs:3991:19 |
| 6 | 10.3% | LazyCompile: *serializeInto ~/hathora-server/node_modules/db/lib/db.cjs:3352:23 |
| 3 | 5.2% | LazyCompile: *write ~/hathora-server/node_modules/db/lib/cmap/connection.js:417:15. | ... |
The profiler output revealed that the majority of the CPU time was spent deserializing responses from database queries. Digging deeper, we realized that in serving the client request flow, our API server was making over 50,000 database calls per second!
We spent some time optimizing the database interaction layer and managed to cut the database query rate in half. When we ran the test again we now cruised to our 10k CCU goal, allowing us to move onto the next milestone.
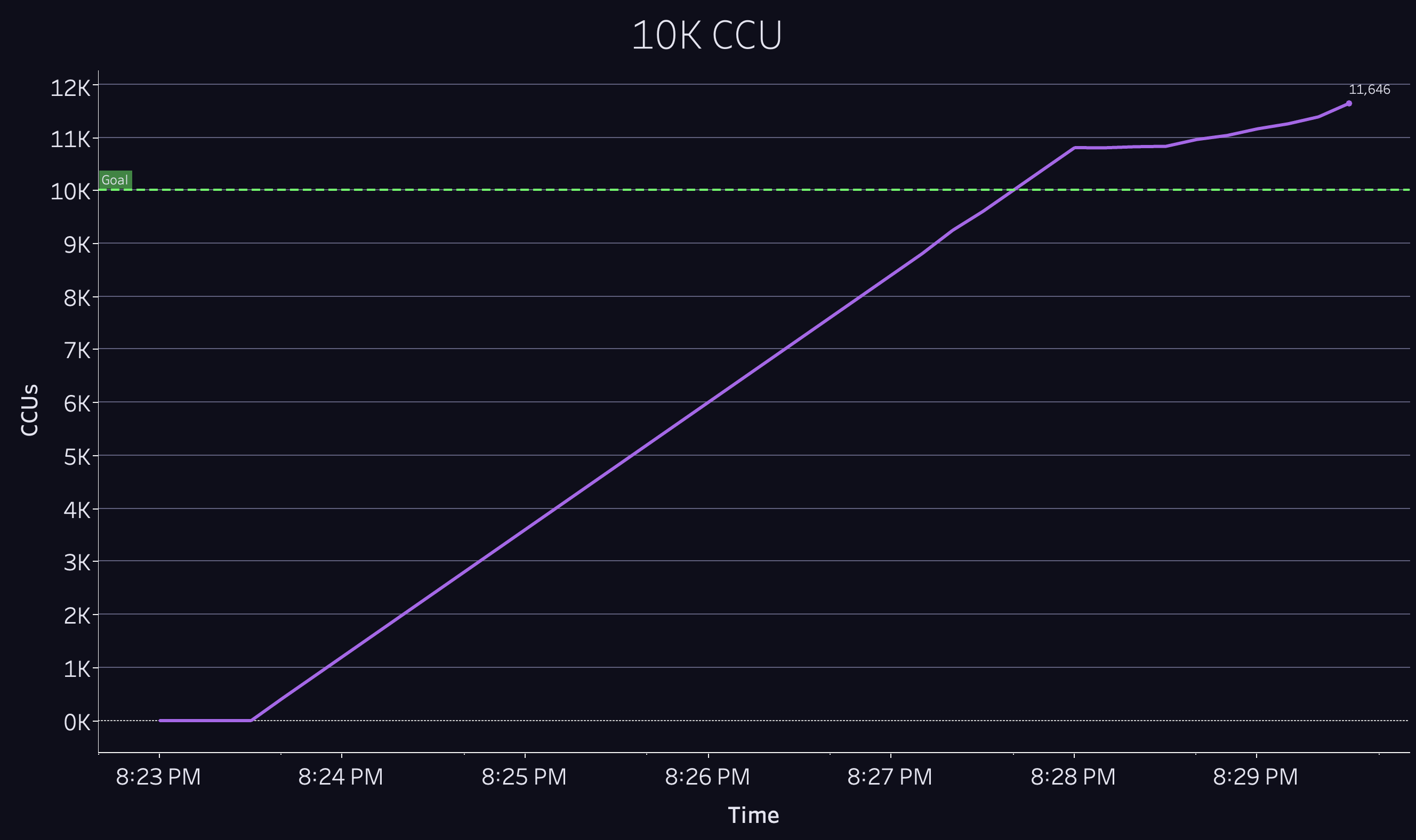
100k CCU
- Problem: Game server sidecars saturated available database connections
- Solution: We switched from pushing metrics to the database to pulling them using a separate metrics backend
Keeping a close eye on our telemetry as we began scaling past 10k CCU, we noticed a concerning trend: the number of open database connections was increasing quickly, which added stress to our database and also put us at risk of hitting the maximum number of connections allowed.
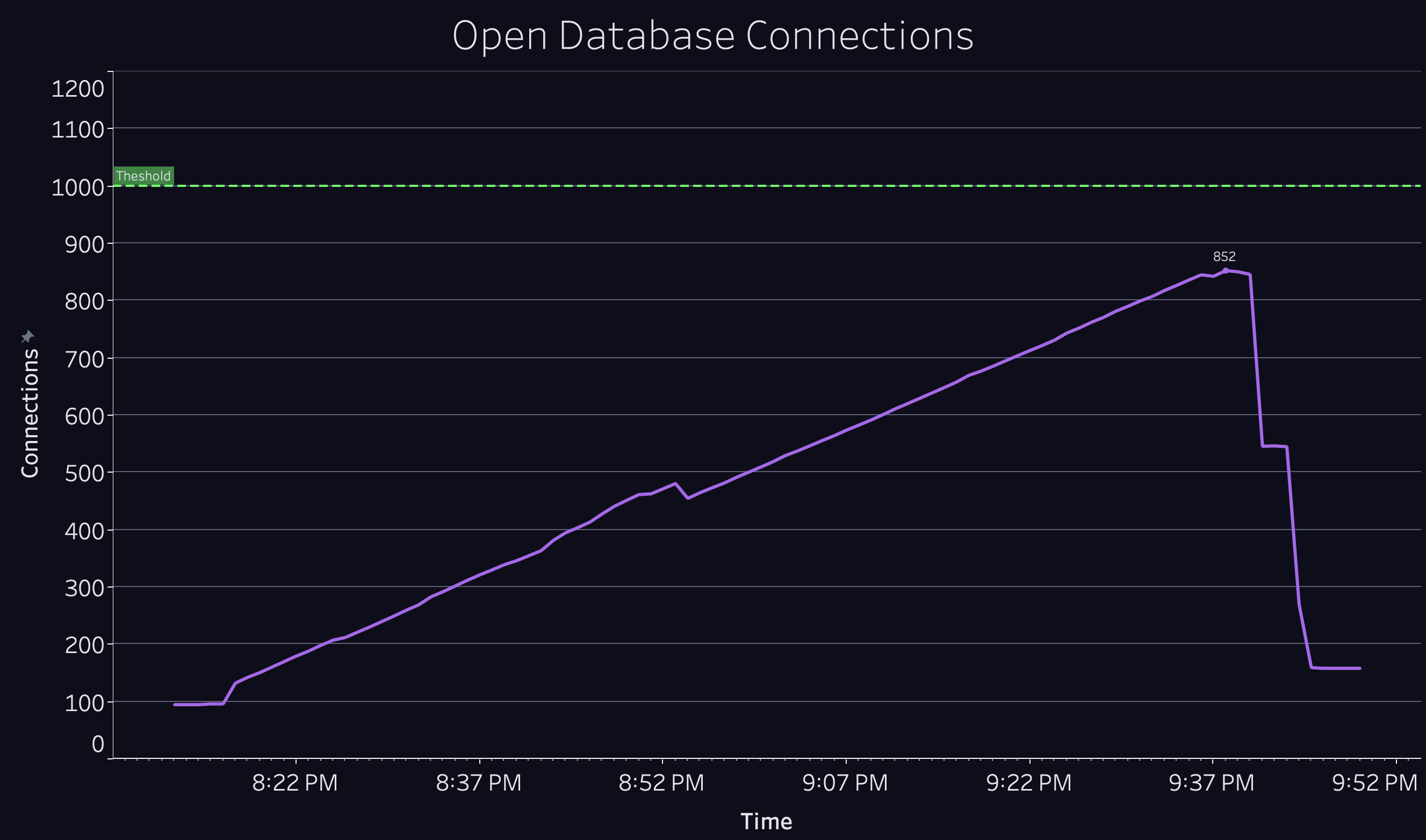
These connections originated from a sidecar that runs alongside each process to handle TLS, monitor connections, and collect metrics. The sidecar required a persistent database connection to write those metrics, and since each new process had its own sidecar with its own database connection, the number of connections was increasing linearly.
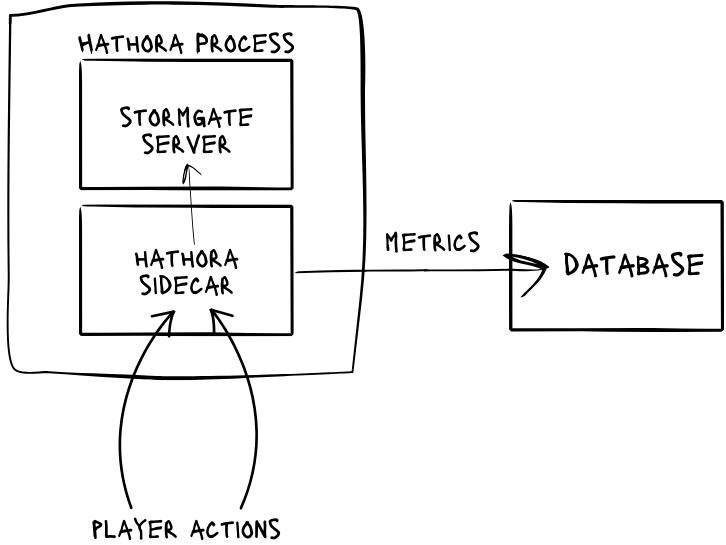
We moved from a model where we push the data into our database to one where we pull from processes using a dedicated metrics backend which supplies and aggregates these metrics on demand. After making this change, we hit our 100k target and were ready for the final boss: 1M CCU.
1M CCU
- Problem: CPU maxed out on our Kubernetes control plane
- Solution: We rightsized the worker and control plane infrastructure to handle the increased traffic
About halfway to 1 million, we saw API calls begin to fail and started receiving alerts indicating Kubernetes issues. We looked at our Kubernetes control plane, and saw that the CPU had steadily increased and eventually maxed out.
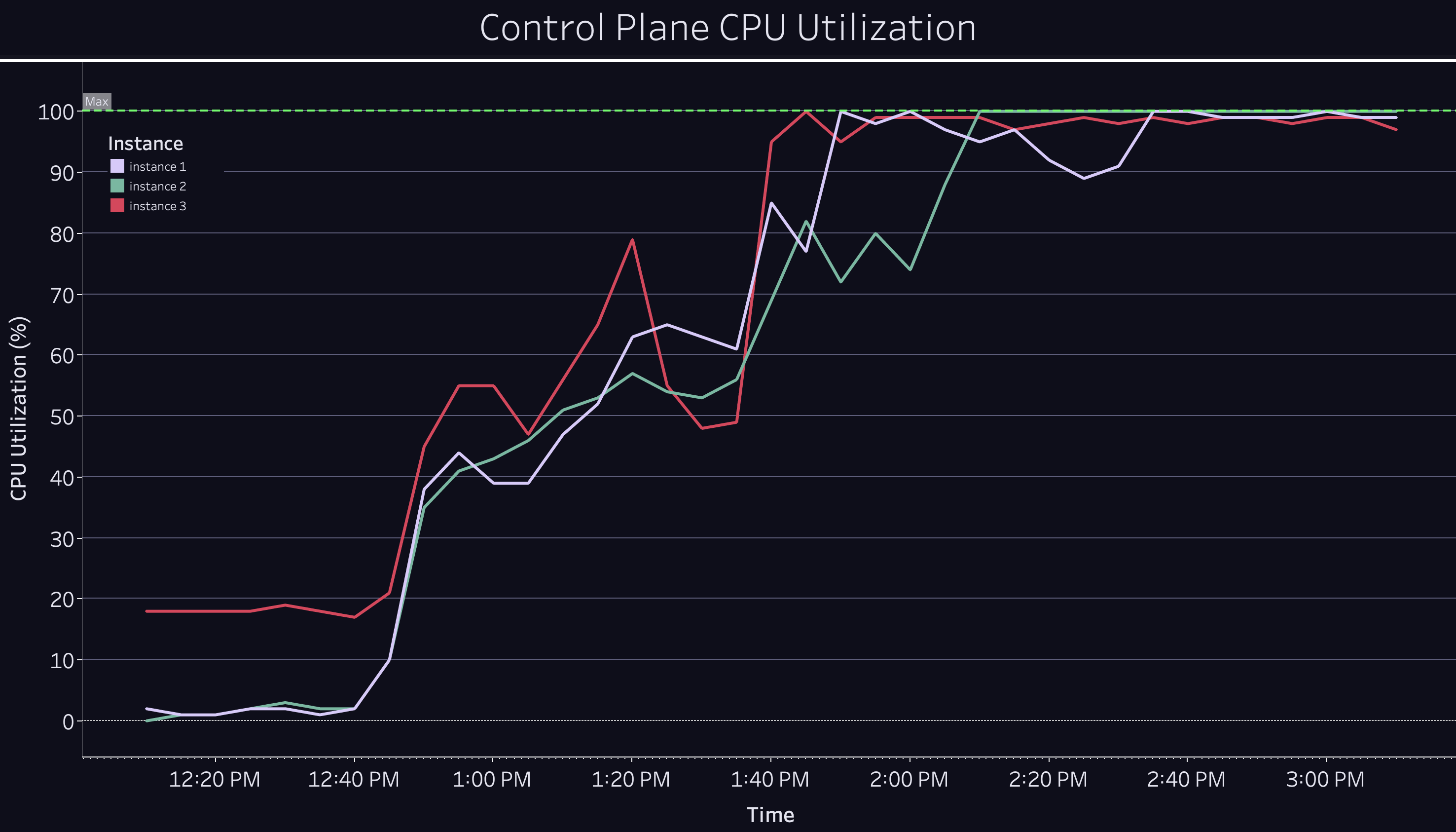
Kubernetes’ CPU usage scales with the number of worker nodes. This is for two reasons:
- Each node is responsible for reporting its capacity and status to the control plane, which means more requests are hitting it.
- In the worst case, the control plane needs to look at every node when scheduling a pod to determine where there is capacity.
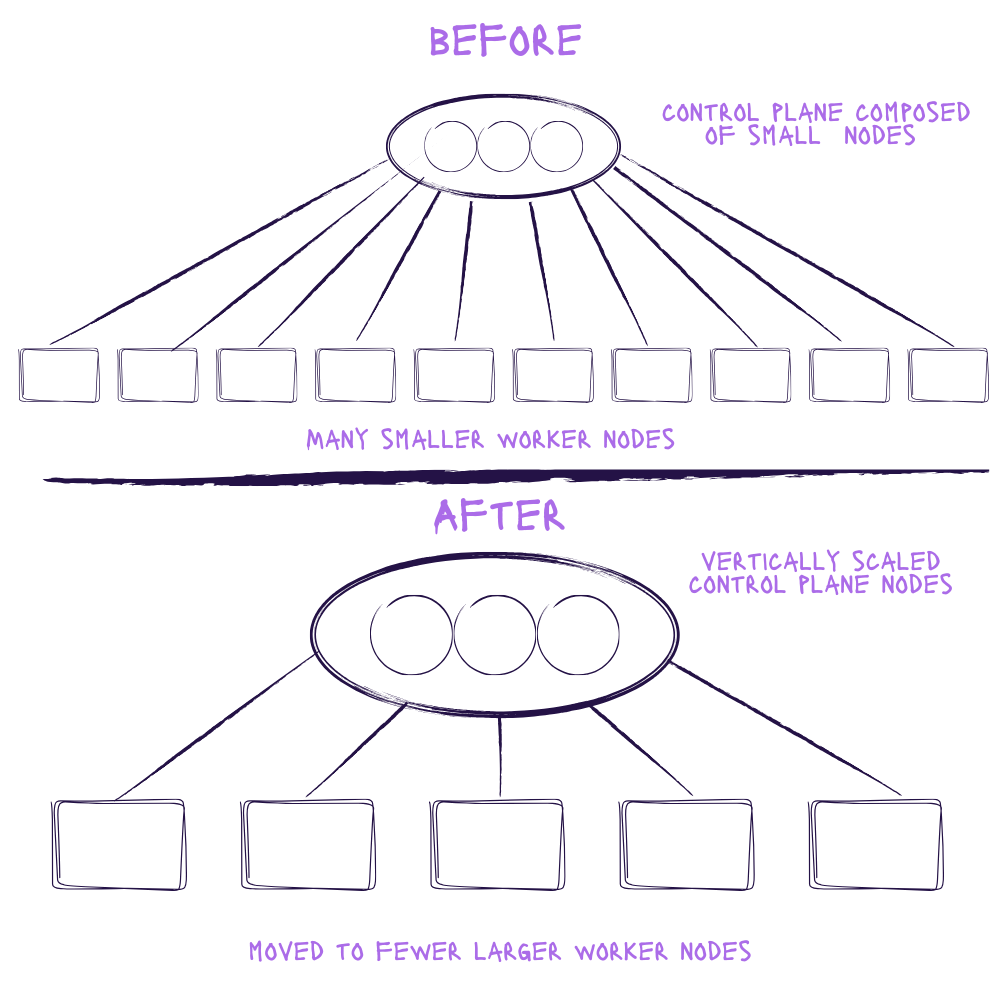
To eliminate the CPU bottleneck and prepare for unexpected demand surges, we:
- Vertically scaled the Kubernetes control plane by switching to machines with more resources.
- Increased each individual node size to reduce the number of nodes the control plane has to manage.
By increasing the size of each individual node, we also reduced per-node overhead and consolidated image caching, allowing us to schedule new rooms faster.
We also have the ability to add new clusters, giving us a way to scale horizontally so that we're not limited by the amount of nodes a single cluster can handle.
With this last obstacle out of the way, we ran the test again, and the results speak for themselves:
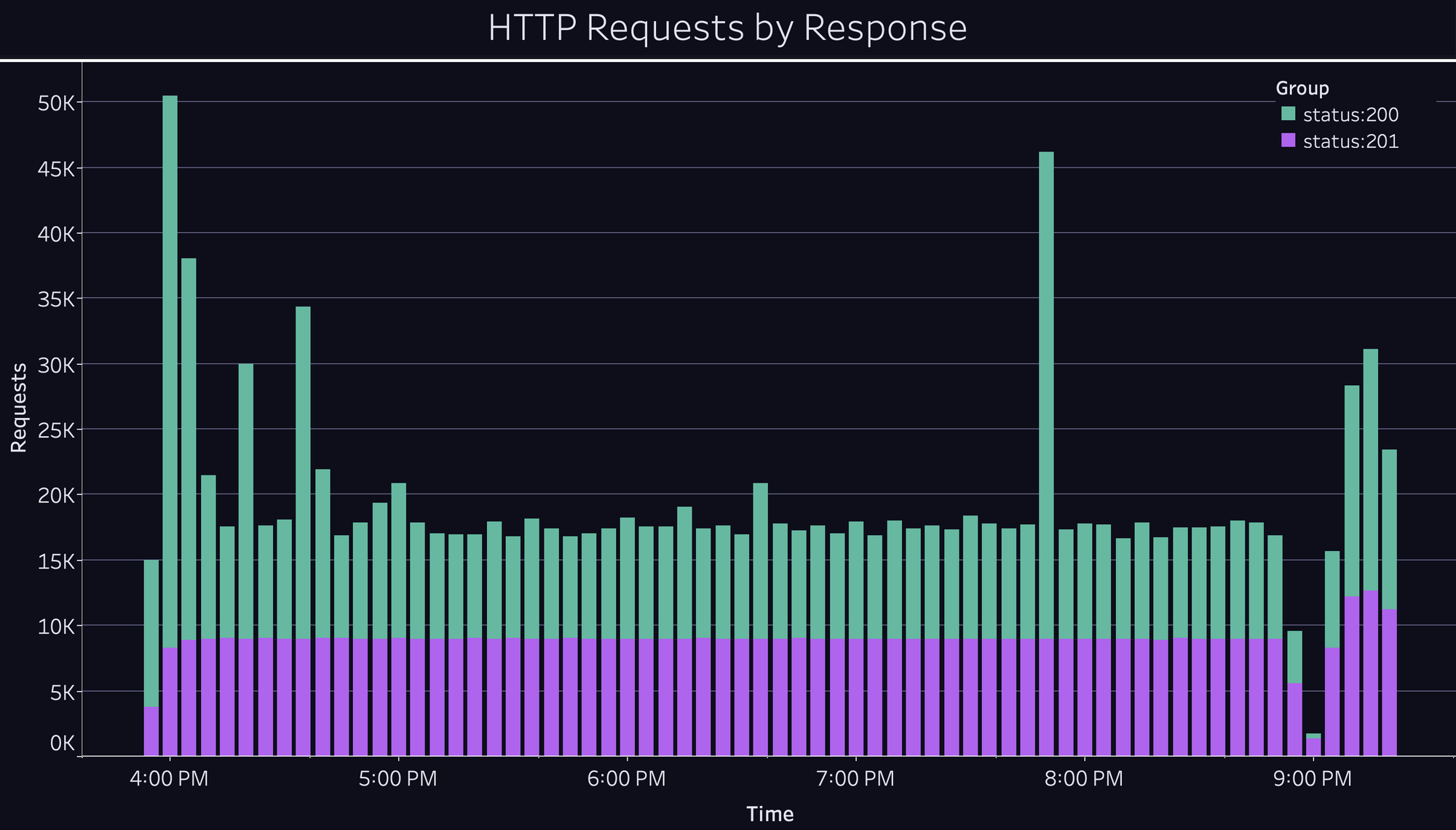
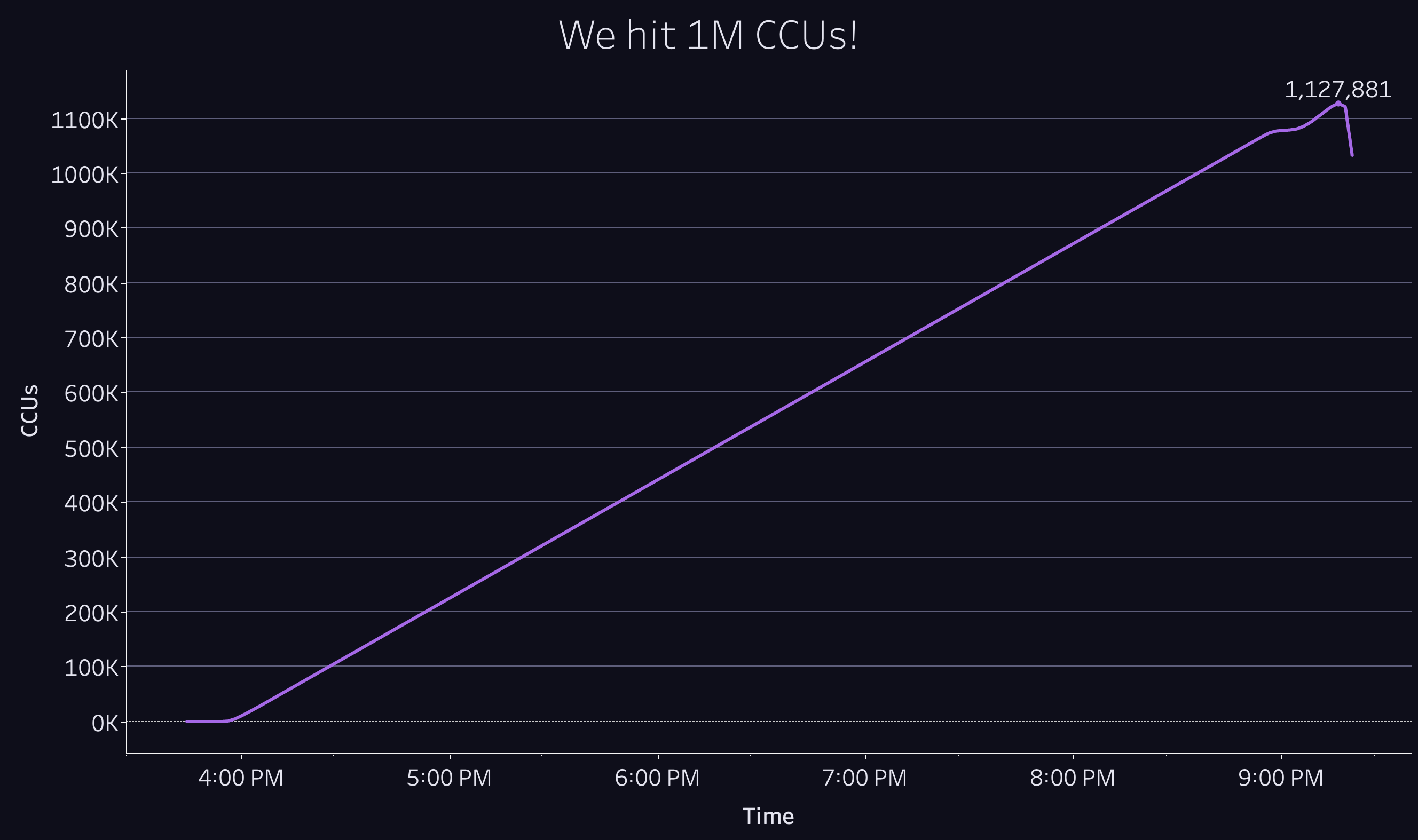
We were thrilled to see the platform scale up so smoothly, and we suspect it could have continued well past the 1.1M CCU that we cut it off at. With renewed confidence in the product we’ve built, we’re excited to onboard more game developers and studios so that they can create amazing games without worrying about scale.
We’re launch ready and you can be too
At this point we know that out platform can support one million concurrent users, and that we’ll have peace of mind on Stormgate’s launch day.
We want to help other studios feel the same confidence as Frost Giant on their own launch days, and we built a useful client test harness that is easily reusable. If you have a multiplayer game and you want to make sure it can scale, please reach out to us at hello@hathora.dev. We would love to partner with you to perform a similar test for your next hit.


