Persistence for Ephemeral Game Servers

About the Guest Author
Mike is a contributor to the Hathora Unreal SDK, and the Lead Developer of Redwood, a multiplayer backend for MMOs, match-based games, and everything in between.
Without persistent data, online games would only have usernames and maybe avatars. Worlds wouldn't be able to reload after a game or OS update. Whether you're using Hathora for ephemeral matches or persistent worlds, you usually need persistent data to at least keep track of player progression and the player's appearance (but likely much more).
Since Hathora's servers are purely ephemeral [for good reason], we need to add additional components to get persistent data:
- Configuring the servers during creation to give them state
- An external place to store the data
- Methods to retrieve the data
In this post, we'll talk about the different types of persistence and how best to integrate them with Hathora's ephemeral game servers.
Key Points
Here's a quick summary of the takeaways this post goes into further detail about:
-
Hathora's simple, fast game servers are ephemeral, so you need external storage to handle game data persistence
-
You'll need a game backend to securely configure the game server to load the correct persistent data
-
While it's possible to use USaveGame/PlayerPrefs/direct file storage for server data, it's recommended to use a database
-
While you can connect to the database directly from the game server, consider using a sidecar or backend to manage the connection and querying
-
Considering using an off-the-shelf backend like Redwood so you don't have to reinvent the wheel
An Overview of Persistence
Persistence is just the fancy word for saving and loading game data to some form of storage. It's how player progression is saved and restored between play sessions or how a server's world state can be reloaded after a version update.
There are many specific ways you can persist data, but they all boil down to two main types:
- Directly saving/loading data to files on disk
- Using a service that handles where/how the data is stored in memory and/or on disk
Many service-based methods are databases, which provide methods to query and modify data in a modular and efficient way, and there are some databases that are stored directly via files on disk without an additional process running (e.g. SQLite).
Using a Game Backend
Unless you want your clients to have complete control of when servers startup and how they're configured, you're going to need a game backend to manage those details. Game backends are separate long-running services that are either self-hosted or managed by a 3rd party (a.k.a Game Backend as a Service - GBaaS). They provide all of the extra functionality and data that isn't in the game server code itself, such as authentication, matchmaking, and game server management.
When it comes to integrating with Hathora, the backend is responsible for:
- Calling the
CreateRoomHathora API endpoint when a match is made or a persistent world needs to created - Providing an initial
roomConfigwith the necessary info so the server can load the correct persistent world data - Providing a secure auth method so cheaters can't pretend to be different players and can't enter servers they weren't assigned to
- Depending on your game, providing the associated player data when they connect to the server
Files on Disk
Being the easiest to implement and troubleshoot, files on disk are the most common way to persist data in single player games. Some multiplayer games, like Minecraft, will also store the files on disk for the server, but this requires a persistent disk volume for the game server.
Since Hathora's servers are completely ephemeral, writing to disk would still need that file to be transmitted to some other storage service to be persisted (e.g. a S3-compatible bucket); at that point it would be a waste of compute resources to even write to disk in the first place.
Even if we could write to disk, this method is the least scalable since most data formats require reading the entire file into memory of the game server instead of offloading those resources into another process/service.
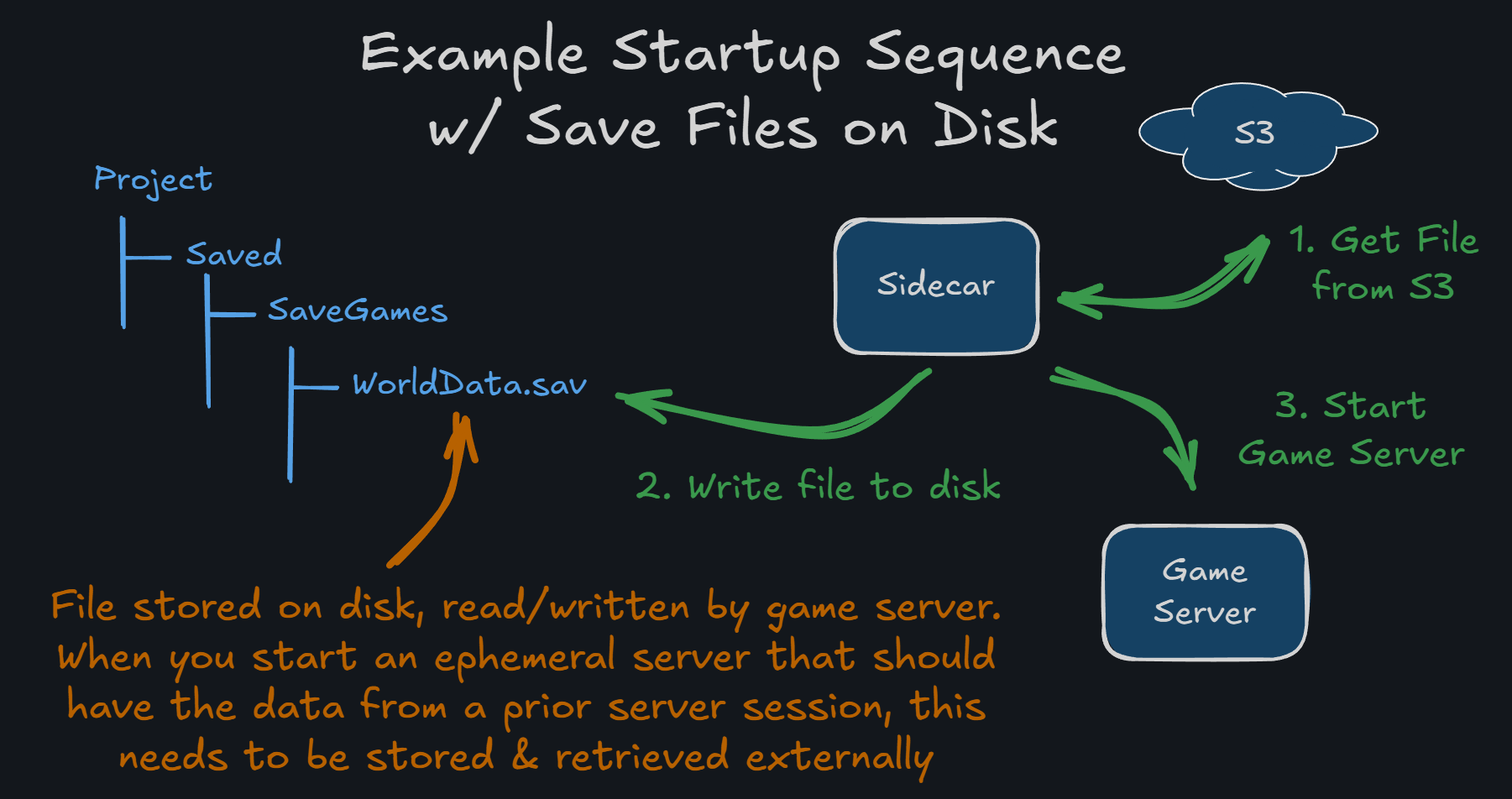
However, it's still an option if you're integrating an existing game to using Hathora that uses file-based persistence. See an example integration below.
Service-based Data Stores
Key-Value Stores (Redis, Firebase Firestore, EOS Player/Title Storage, etc.)

While object stores can be considered a type of key-value store, I like to keep them separate as they usually serve different use cases. Key-value stores are a type of database, usually stored in-memory with fast lookups (and sometimes persisted to disk as a fallback), where a key defined by any string is associated with some string value. The values are preferably smaller (in the bytes-kilobytes range), with object stores being used for larger blobs of data (megabytes-gigabytes). Depending on how you structure your data, these can be more efficient than querying a database, but they are limited in their querying capabilities.
Queryable Databases (PostgreSQL, MongoDB, etc.)
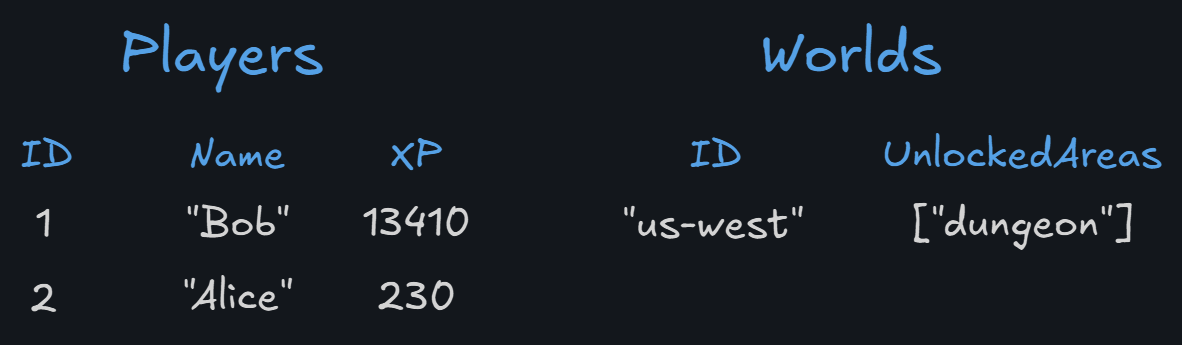
Queryable databases primarily segment into either relational or document stores. These are almost always stored to disk with some in-memory caching for faster lookups. These are the most flexible and scalable, but also the most complex to set up and maintain. They have a query language to quickly locate and aggregate data in a selective manner.
For example, I'd recommend a SQL table for the player's character, but have 1
data field that is of type jsonb that holds all of the data (inventory, gear, experience) instead of having individual fields for each of those.Object Stores (AWS S3, Cloudflare R2, etc.)

Object stores allow you to store raw files (a.k.a. objects or blobs). While most of us are familiar with services like Google Drive and Dropbox, these are not commonly used for applications like live service games. More commonly, games will use services that have an S3-compatible API. These have the least querying capabilities as you usually need to load entire files to find a small piece of information you need.
Redis for ephemeral data (e.g. matchmaking and parties)
PostgreSQL for the persisted data (e.g. player data and other backend metadata)
S3 for large file storage (e.g. videos not packaged with the game)
Redwood also abstracts these persistence services so that you can use the same API calls from the game server but use for faster and easier, but less scalable, alternatives for fast Windows-based development iterations (respectively: Memurai, SQLite, and direct file storage).
Integration with Hathora
Integrating Files on Disk
While I don't recommend this path for ephemeral game servers, if I had to use files on disk for storage, I would write a simple script (e.g. Bash, Python, Node.js) and set that as the CMD/ENTRYPOINT for the Hathora Deployment Dockerfile. The script would use a tool like s3cmd to download the file from a S3-compatible bucket, launch the game server process, and then upload the file when the game server process exits.
Sidecars are also helpful for handling unexpected crashes of the game server, whether that's persisting a final state, invalidating data that may have not fully finished persisting, reporting the error, etc. These don't replace exception handling within the game server process, but definitely are a crucial compliment.
Below is a sample of what this might look like with an Unreal project and a Node.js sidecar script. We've included both the Dockerfile and sidecar.js files which would be part of the tarball you upload to Hathora. You would also include the LinuxServer folder that was generated when you packaged your Linux dedicated server in Unreal. Your tarball might look something like this:
hathora-deployment.tar.gz/
├── Dockerfile
├── sidecar.js
└── LinuxServer
├── Engine
│ ├── ...
├── Project
│ ├── ...
├── ProjectServer.sh
└── ...hathora-deployment.tar.gz
FROM ubuntu:24.04
RUN apt update
RUN TZ=UTC apt install -y s3cmd nodejs
# Copy the Unreal game server contents
COPY --chown=nonroot:nonroot ./LinuxServer /home/nonroot/server
# Copy the sidecar contents
COPY --chown=nonroot:nonroot ./sidecar.js /home/nonroot/sidecar.js
# Ensure the server executable is actually executable
RUN chmod +x /home/nonroot/server/Project/Binaries/Linux/ProjectServer-Linux-Shipping
# Expose the game port
EXPOSE 7777/udp
# We launch the sidecar first which will launch the game server
ENTRYPOINT ["node", "/home/nonroot/sidecar.js"]Dockerfile
const path = require("path");
const execSync = require("child_process").execSync;
// Retrieve the S3 configuration; this assumes the room was created
// with a room config that has all these details prefilled from your
// backend/middleware/matchmaker. Some of these could use Hathora's
// custom environment variables: https://hathora.dev/docs/guides/access-env-variables#configure-variables
const roomConfig = JSON.parse(process.env.HATHORA_INITIAL_ROOM_CONFIG);
const s3Endpoint = roomConfig.s3.endpoint;
const s3Region = roomConfig.s3.region;
const s3Bucket = roomConfig.s3.bucket;
const s3AccessKey = roomConfig.s3.accessKey;
const s3SecretKey = roomConfig.s3.secretKey;
// this could be some unique ID for the game server to store
// its data separately from the other servers
const s3BasePath = roomConfig.s3.basePath;
const baseDirectory = "/home/nonroot/server";
const projectName = "Project";
// Download the file
const createArgs = (command) => {
const remotePath = `s3://${s3Bucket}/${s3BasePath}/WorldData.sav`;
const localPath = path.join(baseDirectory, `${projectName}/Saved/SaveGames/WorldData.sav`);
return [
`--host=${s3Endpoint}`,
`--region=${s3Region}`,
`--access_key=${s3AccessKey}`,
`--secret_key=${s3SecretKey}`,
command,
command === "get" ? remotePath : localPath,
command === "get" ? localPath : remotePath
].join(" ");
};
execSync(`s3cmd ${createArgs("get")}`);
let exitCode = 0;
try {
// Launch the game server
execSync(path.join(baseDirectory, `${projectName}/Binaries/Linux/${projectName}Server-Linux-Shipping`), { stdio: "inherit" });
} catch (e) {
// Handle the error
console.error(e);
exitCode = 1;
} finally {
// Upload the file
execSync(`s3cmd ${createArgs("put")}`);
}
process.exit(exitCode);sidecar.js
Integrating Service-based Data Stores
If you're using a service-based data store like a relational database, the setup is a bit more involved.
You can either connect directly to the service from your game server or create an additional API for the sidecar or backend to query the service on behalf of the game server. Both are valid implementations and each have their pros and cons. Connecting directly in the game server usually is implemented with higher coupling and creates a higher cost to switch services. Proxying the requests through the sidecar or backend creates an additional set of API, but allows for more flexibility to switch providers later without having to update the game server.
When you're using a service-based data store, the data is retrieved while running the game server (and optionally sidecar if you choose to have one) rather than being a file that needs to be stored before the game server starts.
Adding an API to a Sidecar
In the below diagrams, we show a setup that has 1 Room per Hathora Process and a sidecar that maintains a connection to a backend and a database that's shared with the backend. This requires a new API between the game server and sidecar which can be implemented with various different protocols. I recommend choosing something you're familiar with and ideally has native support or a mature 3rd party plugin for your game engine for easy integration. Here's a quick comparison of popular choices (but please do your own research; there are a ton of better comparisons online):
- REST: easiest to implement, ephemeral connections, lots of support
- WebSockets: persistent connections (which means not requiring constant auth checking), usually supported
- gRPC: hardest to implement, persistent connections, data efficient (which means faster overall), less supported
I personally recommend using Node.js/Bun since it's one of the more popular ecosystems for cloud service libraries, and hiring developers to support it is generally easier than other languages/runtimes. WebSockets are a great middle-ground for a protocol in terms of maintainability, support, and learning curve.
Provisioning a Server with Persisted World Data
Since there are many protocol, protocol library, sidecar runtime, and architecture choices (many of which are opinionated), I figured sequence diagrams would be more helpful than a code sample here.
The below diagram outlines what happens in between a player queuing for a match and receiving the server connection details:
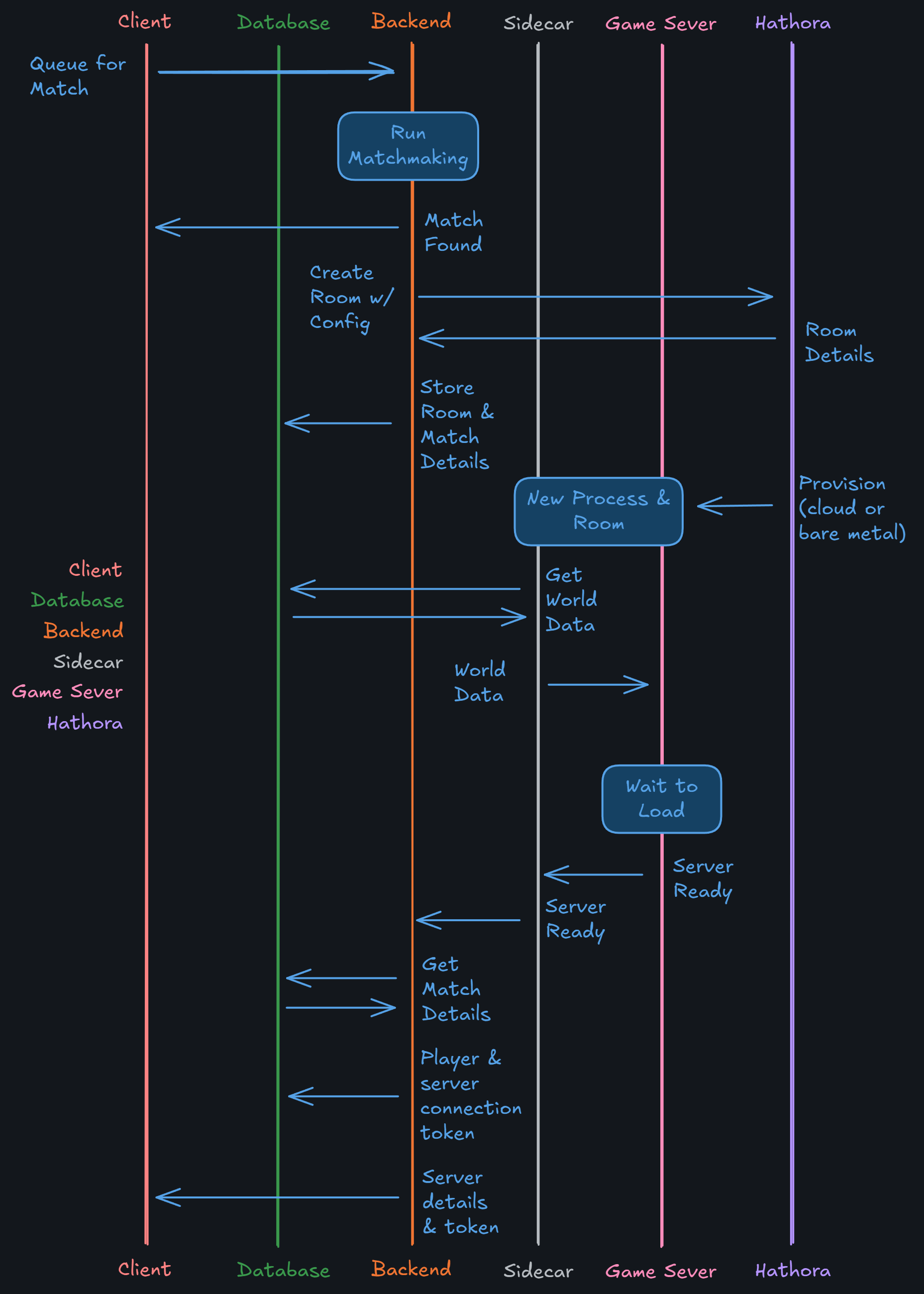
The Create Room w/ Config message the Backend sends Hathora should include (via the initial roomConfig):
- An ID the backend created for the session (which is usually linked to an ID from the matchmaker)
- Auth details for the server/sidecar to connect to the backend
- Auth details for the server/sidecar to connect to the database (unless you proxy your DB calls through the backend)
- You can provide more info here, but the sidecar can also retrieve it from the backend/database when it has started using the other config
The Player & server connection token stored in the database is used as an authentication handshake between the player, game server, and backend. The purpose of this token is to not only authenticate the player with the server, but also ensure the player is connecting to the correct server. Otherwise a player could connect to any server if it knew the connection details. The token should also expire quickly and be single-use to help prevent man-in-the-middle and replay attack vectors.
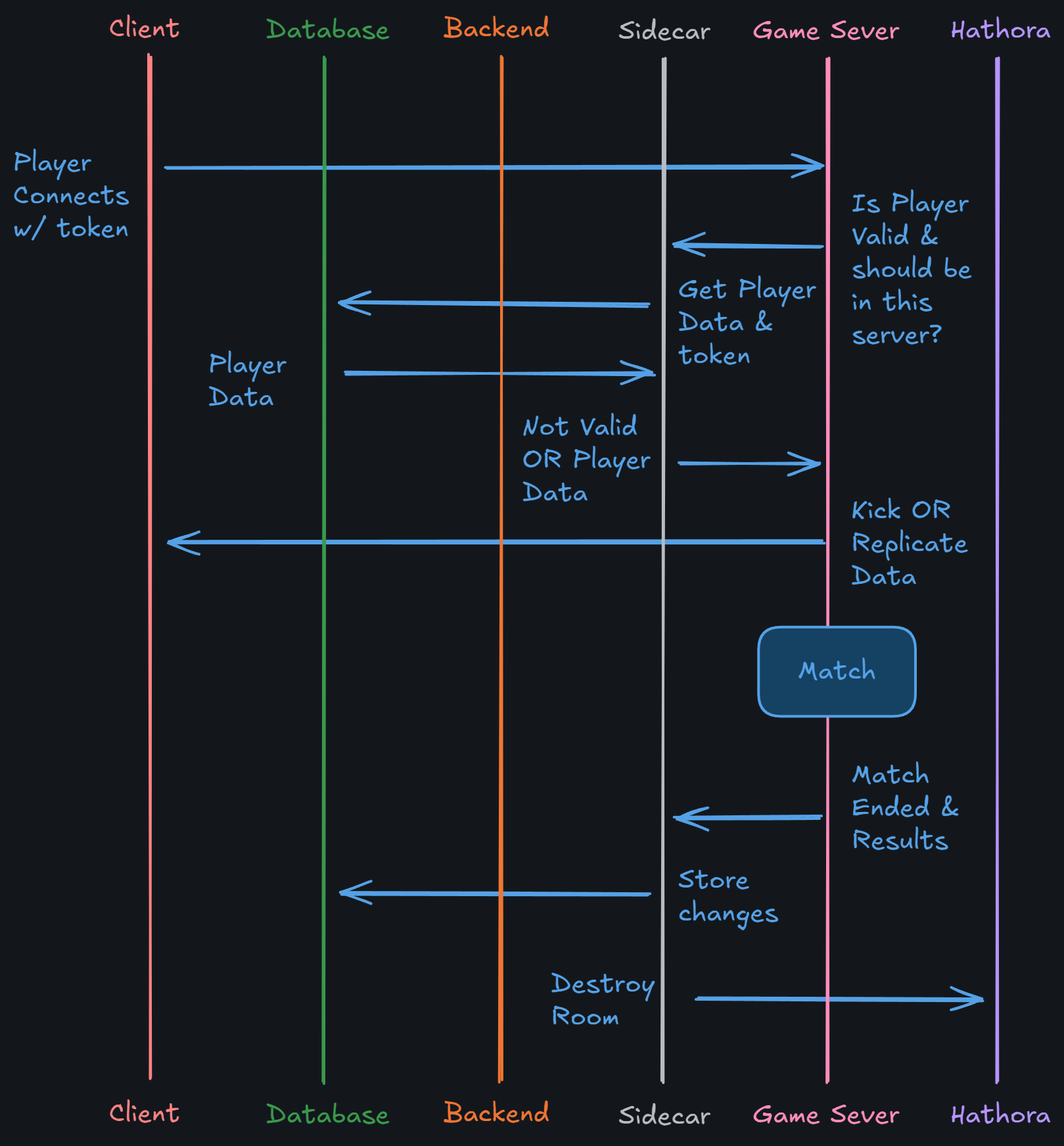
Connecting a Player to the Server
Once the player has the server IP, port, and connection token, it's fairly straight forward. The player joins with the token, it gets validated, and simultaneously provides the player data to the server to replicate to the client. Eventually the match ends and we persist any necessary data changes.
Closing Thoughts
Takeaways
-
Hathora's simple, fast game servers are ephemeral, so you need external storage to handle game data persistence
-
You'll need a game backend to securely configure the game server to load the correct persistent data
-
While it's possible to use USaveGame/PlayerPrefs/direct file storage for server data, it's recommended to use a database
-
While you can connect to the database directly from the game server, consider using a sidecar or backend to manage the connection and querying
-
Considering using an off-the-shelf backend like Redwood so you don't have to reinvent the wheel
Next Steps
Checkout the CreateRoom Hathora API call to see how your backend can start a server with an initial configuration. This gets injected into the Hathora Process as the HATHORA_INITIAL_ROOM_CONFIG environment variable.
Reach out on the Hathora Discord server or at contact@hathora.dev if you have any integration questions.
Redwood takes into consider all of these authentication handshakes and game data solutions, but it also comes with:
- Matchmaking and Queuing
- Open-world Zoning/Sharding
- Instanced Dungeons
- Cloud deployment scripts
- and more to come!
Redwood also provides a turnkey integration with Hathora while also supporting running uncooked game servers locally all using the same Redwood API calls from the game server, most of which are handled for you with the Redwood Unreal plugins (of course you can opt-out and call the APIs yourself).
Redwood was designed to provide a great developer experience so you don't have to implement all of these details from scratch and can just focus on building your game and, if you choose to, customizing the backend to add support for next gen online experiences.
Give Redwood a try today; if you decide it's not for your game you won't ever owe anything. Want to chat with me? Connect with me on LinkedIn or at mike@incanta.dev.


