Modern Cloud for Multiplayer Games


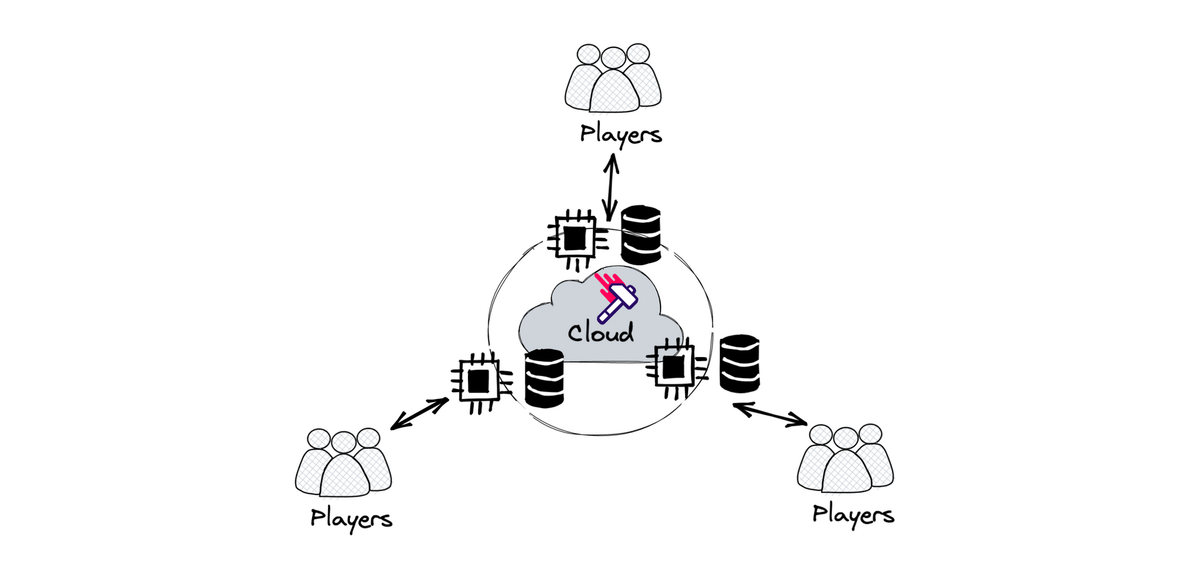
Over the years, much has been written on the internet about developing multiplayer games. However, there is surprisingly little information available when it comes to deploying and managing production game infrastructure.
Given the nature of multiplayer games, traditional backend infrastructure techniques often don't apply – multiplayer games are inherently stateful and the latency requirements are extreme. In this article we will explore what "good" looks like for a multiplayer infrastructure stack, looking at it from the lens of a hypothetical studio going through the journey of deploying their game and improving their stack over time.
Alice and Bob
Alice is a Game Developer at a small indie studio, and has been working on Awesome Game, a realtime mobile multiplayer game for months. The game functions similarly to Among Us – someone creates a room and invites their friends to it by sending them the room code.
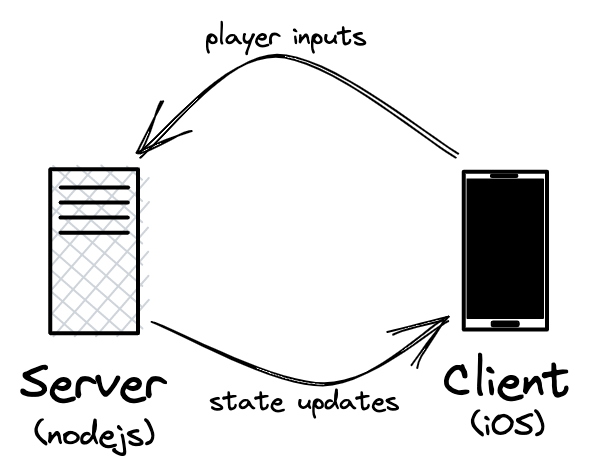
Awesome Game's architecture follows a client-server model. The frontend is an iOS app which is responsible for rendering the game and sending player input to the server. The backend is a Node.js server which processes player input, updates the game simulation in-memory, and broadcasts the game state to all connected players.
The game is finally ready – the graphics look slick, the gameplay is fun and the networking layer is smooth on LAN. She shows it off to Bob, the Product Manager at her studio, and Bob falls in love with it. The next step is to make the game available for players worldwide. Alice submits her iOS build to the App Store for review, and then sits down to figure out how to host the server so that it’s accessible over the internet.
Getting Started
Host server from home
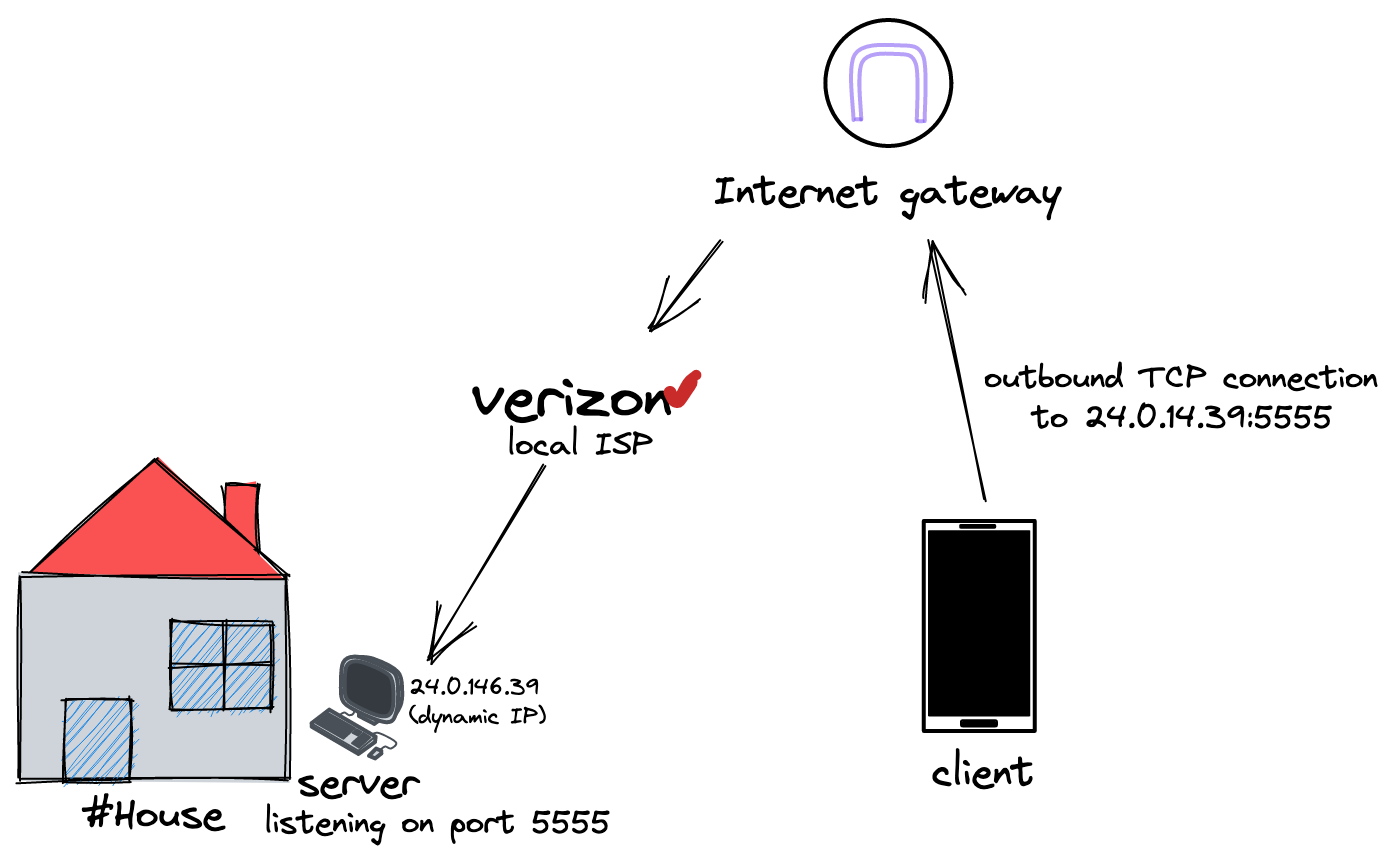
To begin with, Alice figures she can just host the server on her development machine that's sitting under her desk in her home-office setup. After all, that’s where she has been running the server all this time so she knows it works on it, and it won’t cost their studio any money to run it there.
There are a few steps needed to get this working:
- Configure her desktop to never go to sleep since the server needs to be running around the clock
- Find her desktop’s IPv4 address using whatismyipaddress.com and hardcode it as the host to connect to in her iOS client
- Configure her router to port forward port 5555, the TCP port her server listens on, so that her firewall won't block clients from connecting to it
This setup works great for some time but one day Bob reports to Alice that users can no longer connect to the server. To her surprise, Alice finds that her desktop’s IP address has changed! After some research, Alice learns that her public IP address is assigned by her Internet Service Provider (ISP, Verizon Fios is an example of one). It turns out her dog had knocked over the router the night before, and it was assigned a brand new IP when Alice plugged it back in.
Alice quickly patches her iOS client to the new IP address, and Bob emails the users telling them to upgrade their game from the App Store to receive the fix. Alice decides it's time to move the server setup to the Cloud – this experience made her realize how fragile the home setup is.
Host server on AWS
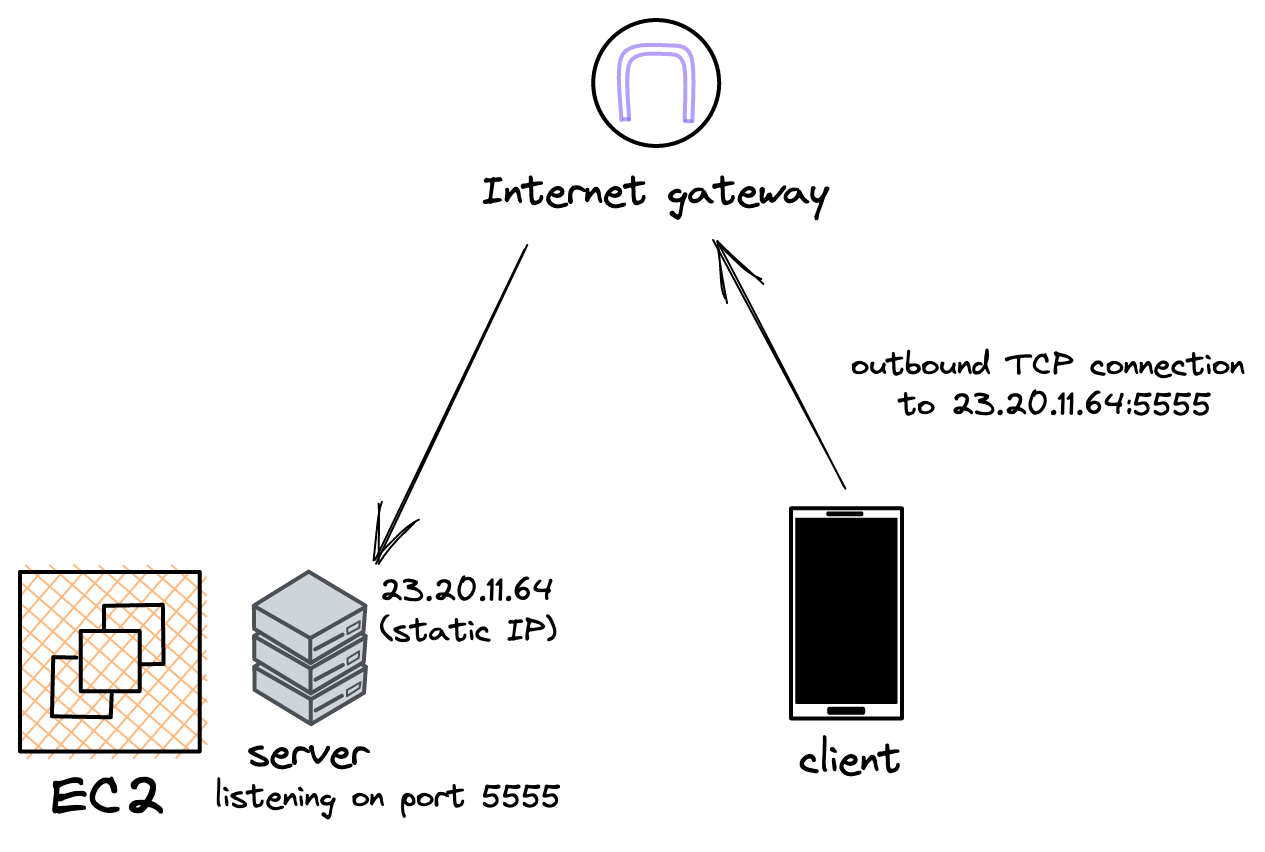
Alice turns to AWS, a popular cloud infrastructure provider. Once she creates her account and logs in to the console, she's immediately confused. What’s a NAT gateway and which subnet should she pick? Key pairs? Security groups? Storage volumes?! The list goes on and on.
Eventually, Alice gets a virtual machine (VM) up and running on EC2. She spends some time configuring the VM: installing the packages she needs for the game server, setting up her bash profile, etc. Next, she copies over Awesome Game's server build to the machine and gets it running. Finally, she obtains a static IP address for her VM and opens up port 5555 for inbound connections. After updating the hardcoded IP in the iOS app, users are back to playing the game again and all seems to be well…
A few months in, Alice receives a panicked call from Bob. He was running some scripts on the VM to parse the game logs, but he accidentally ran a command that caused the VM to become unresponsive. Alice can’t fix the issue and decides to just create a new VM. To her disappointment, she has to run through all the same steps as she took when setting up the original VM, and it takes a full day to get everything working again – all while the game was unavailable to users. After going through this process, Alice decides to find a way to ensure it doesn't happen again.
Docker builds
What Alice’s infrastructure setup is missing is the concept of reproducibility. Right now, her VM is a special snowflake with all kinds of dependencies manually configured by her. This makes it difficult to make a copy of the VM, which is something you may want to do for various reasons such as replacing a VM that had some kind of failure, scaling horizontally by adding multiple VMs, or migrating to a different environment (e.g. upgrading the VM resources, or migrating to a different cloud provider).
Alice has heard that Docker is a technology that aims to solve exactly this problem, so she decides to incorporate it into her setup. She starts by writing a Dockerfile in her project to create a fully bundled image that has all of her application's dependencies in one place:
# use Ubuntu as the operating system
FROM ubuntu:22.04
RUN apt-get install node
ENV NODE_ENV=production
WORKDIR /app
# copy source files
COPY . .
RUN npm install
# build the project
RUN npm run build
# expose the TCP port
EXPOSE 5555
ENTRYPOINT ["node", "index.js"]Next up, she builds a container using the Dockerfile and uploads it to ECR, AWS’s container repository:
docker build . -t $ECR_REGISTRY_HOST:AliceStudios/AwesomeGame
docker publish $ECR_REGISTRY_HOST:AliceStudios/AwesomeGame
To automate this process, Alice runs the same commands inside a Github Action. By doing this Alice has set up something called Continuous Integration (CI) – now her ECR repository will automatically receive the latest Docker container every time she pushes a commit to her Github repository. This both solves the reproducibility problem and removes a manual task from Alice's plate.
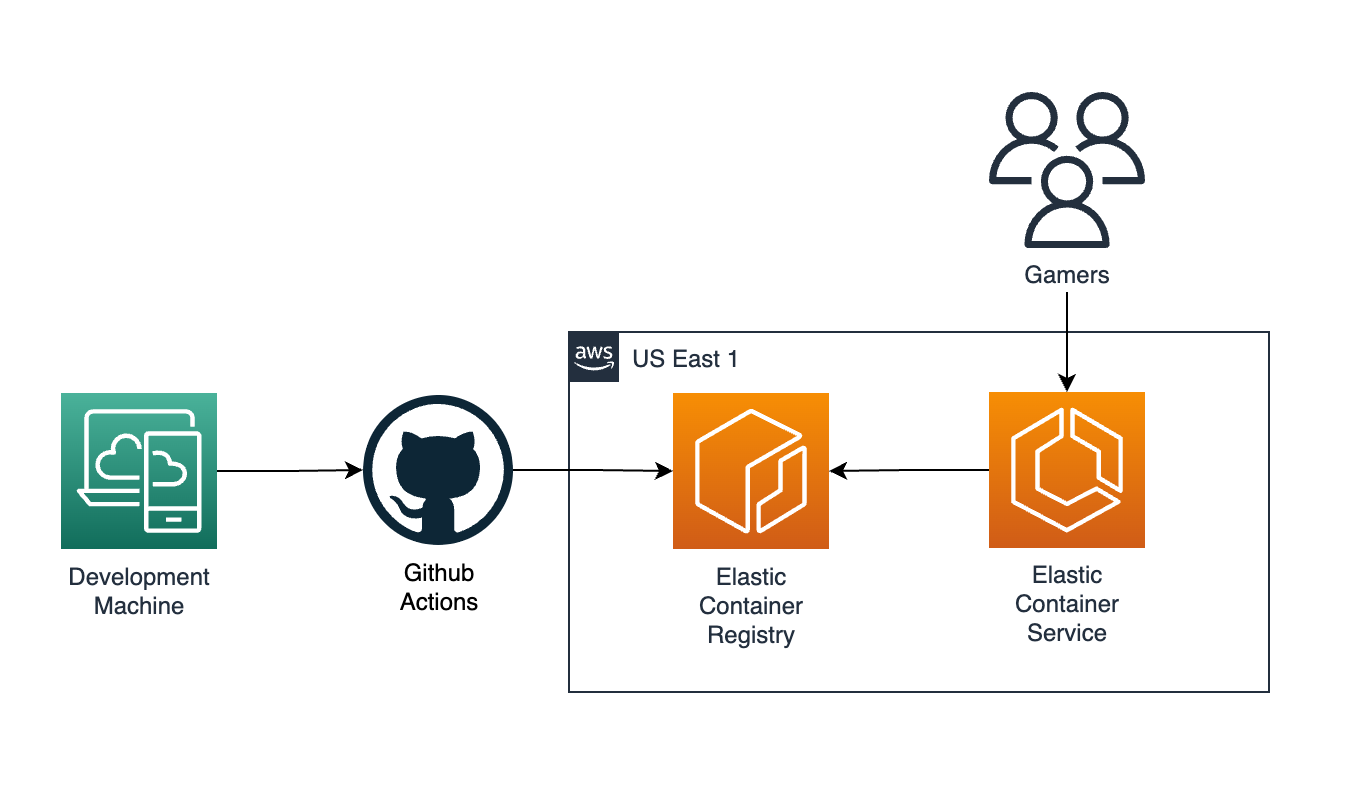
For the final step, Alice creates a cluster in ECS, AWS’s container runner, and sets up a Task Definition so that the latest container from her repository will always be running. So now Alice can get rid of her EC2 VM since she knows that her game server will always be running via her Docker container.
Bob is thrilled to hear that their server infrastructure is now more resilient and stable, and he starts promoting Awesome Game more. Players are loving it, but as the game starts gaining popularity globally, Bob notices a flurry of 1-star ratings coming from gamers outside the US – all of them talk about laggy or glitchy gameplay. Given Awesome Game's server is currently located in the US, players connecting from far away have to wait a longer time for network packets to travel to and from the server. Now it’s Alice’s job to find a solution that can reduce latency for these users.
Global Scale

Multi-region game servers
To address the latency problems, Alice starts by adding two new VMs in different regions. In addition to the previous one in North America, there are now servers in Europe and Asia as well.
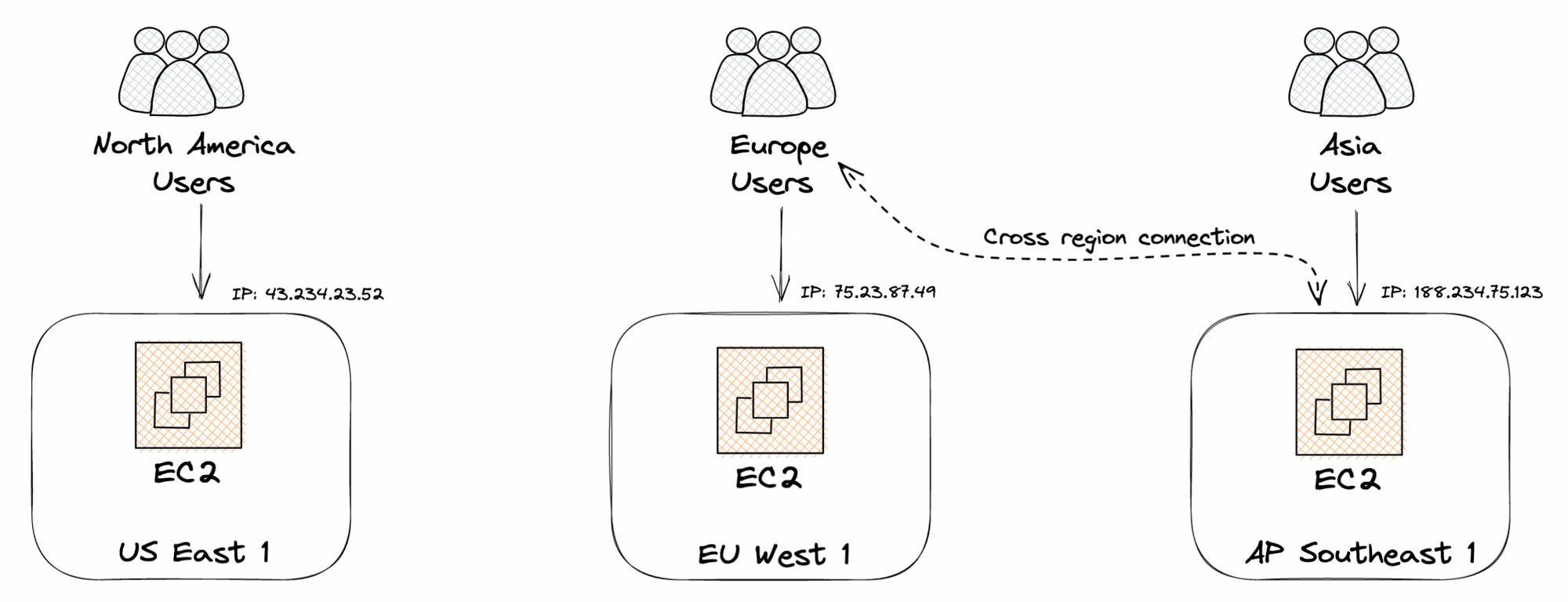
Now servers are closer to players, but Alice now has to figure out how to route clients to the correct VM. To start with, she decides to modify the single hardcoded IP address in the client to be a list of hardcoded IPs, along with the region they correspond to. Now, when players create or join a lobby, they must select the region/IP they wish to connect to from a dropdown.
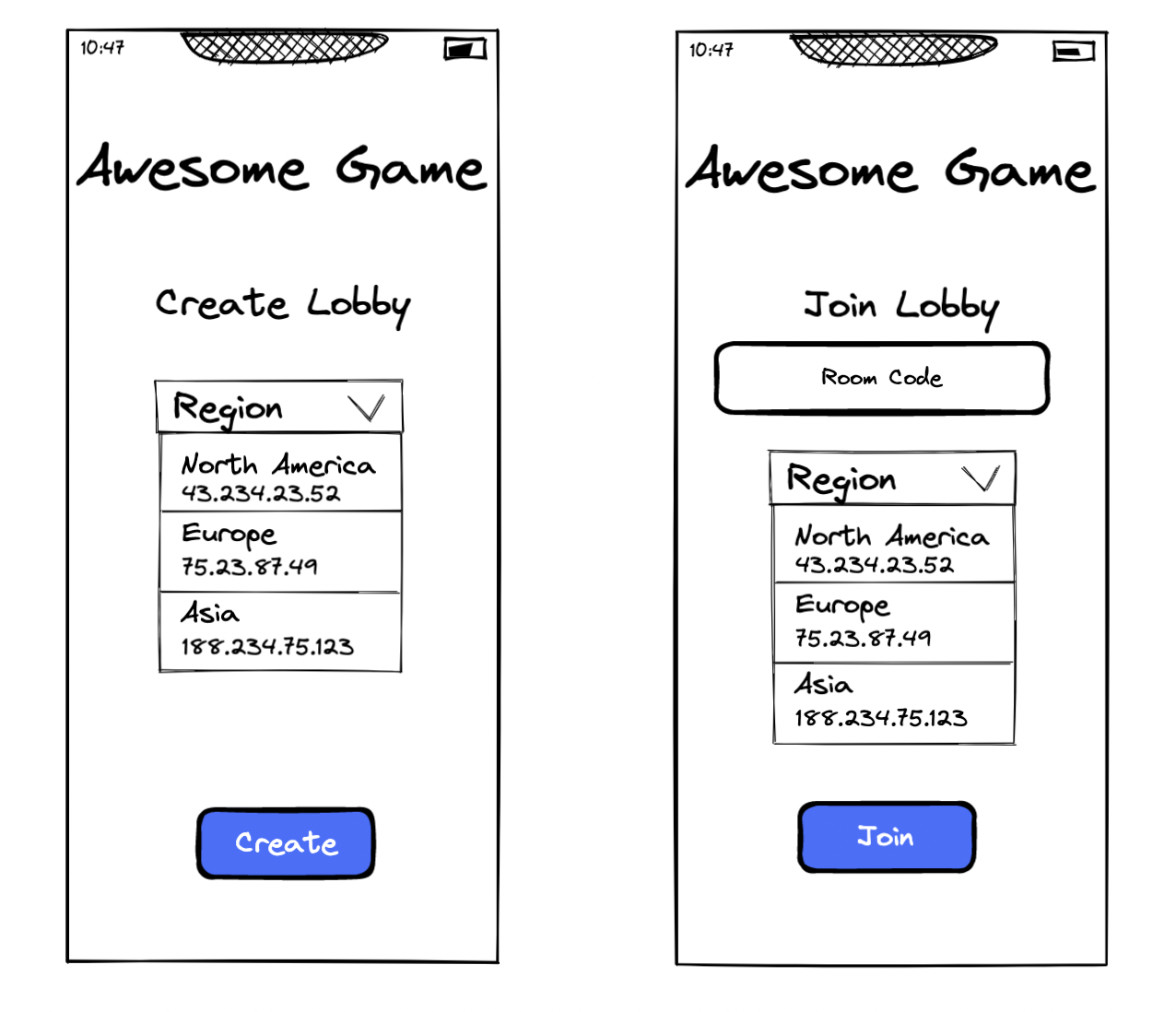
When a player goes to create a new lobby, they must select the region they wish to create it in (probably the region closest to them). Then, they must send this region along with the room code when inviting friends so that they can successfully connect to the lobby.
While this solution works, Bob points out that having players manually select the region every time they create or join a game feels cumbersome, especially if the region list grows large. Alice also doesn't like the fact that adding or removing regions would be a huge pain in this model, since it would require a client update.
Geo-location DNS
While researching how to solve these issues, Alice stumbles upon geo-location DNS routing. Domain Name Service, or DNS, is a map of website names to IP addresses. For example, wikipedia.org maps to 208.80.154.224. So, Alice takes the first step and purchases awesomegame.gg from a domain registrar (like Namecheap). Once purchased, Alice configures awesomegame.gg to point to her 3 VMs around the world.
With Geo-location DNS, clients are only aware of awesomegame.gg, but based on where the DNS query is originating from, the DNS server will respond back with a different ordering of all configured server IPs. The ordering of the IPs in the DNS response correlates with the distance between the user and that server. For example, a user in New York would get the US East server first, while a user in Sydney would get the Singapore server first.
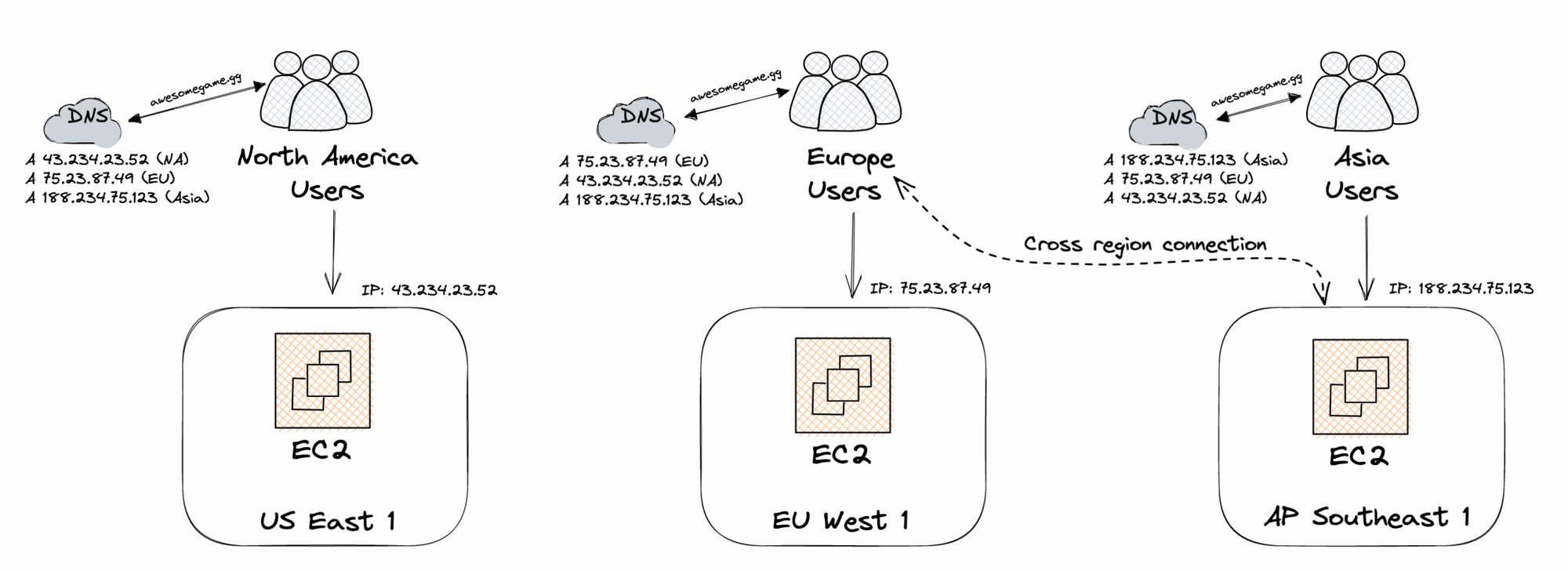
This removes the region selection in the create screen by automatically choosing the region closest to the requesting player. But this doesn't quite solve the join side of the equation, since a game session only runs on a specific server, which might not be the one closest to all clients that are trying to connect.
The simple way around this is to add logic into the client to try connecting to all the game servers that the DNS response comes back with, instead of just using the first response. So the client will simply try connecting to all servers with a specific room code, and the server that has that room code will acknowledge the connection.
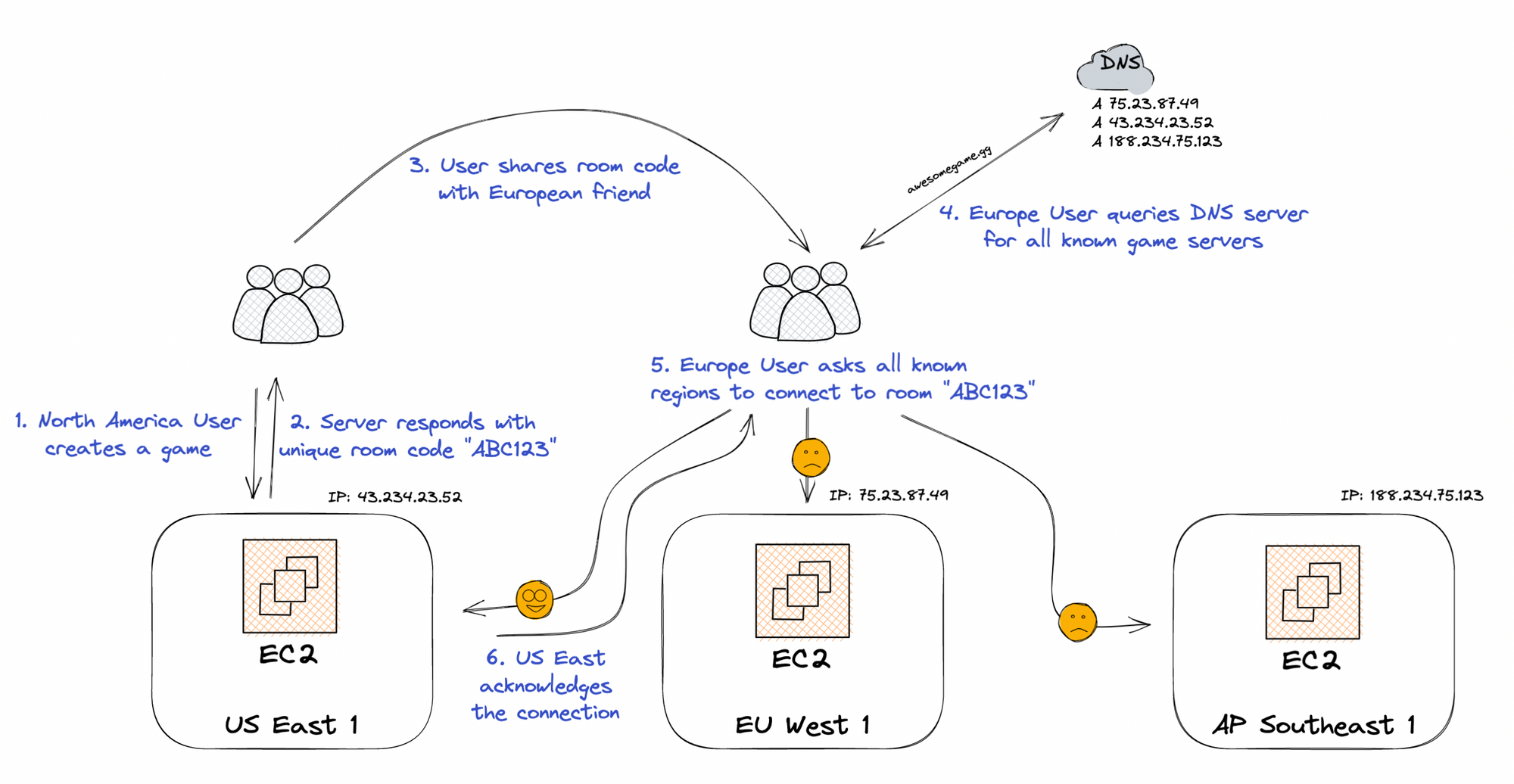
This solution enables Alice to modify the server list without having to update her client code, but the major downside with DNS based routing is that the clients choose how long they want to cache the responses to DNS queries. So, you might end up with clients attempting to hit servers that you’ve already taken out of service.
While players located in the same region now seem to all have a great experience, Bob begins to hear about issues in cases where players play with their friends who live far away from them. While there is some amount of lag that is to be expected given the physical distances, the amount of latency that some players are seeing are above what can be accounted for solely based on the geography.
Edge compute
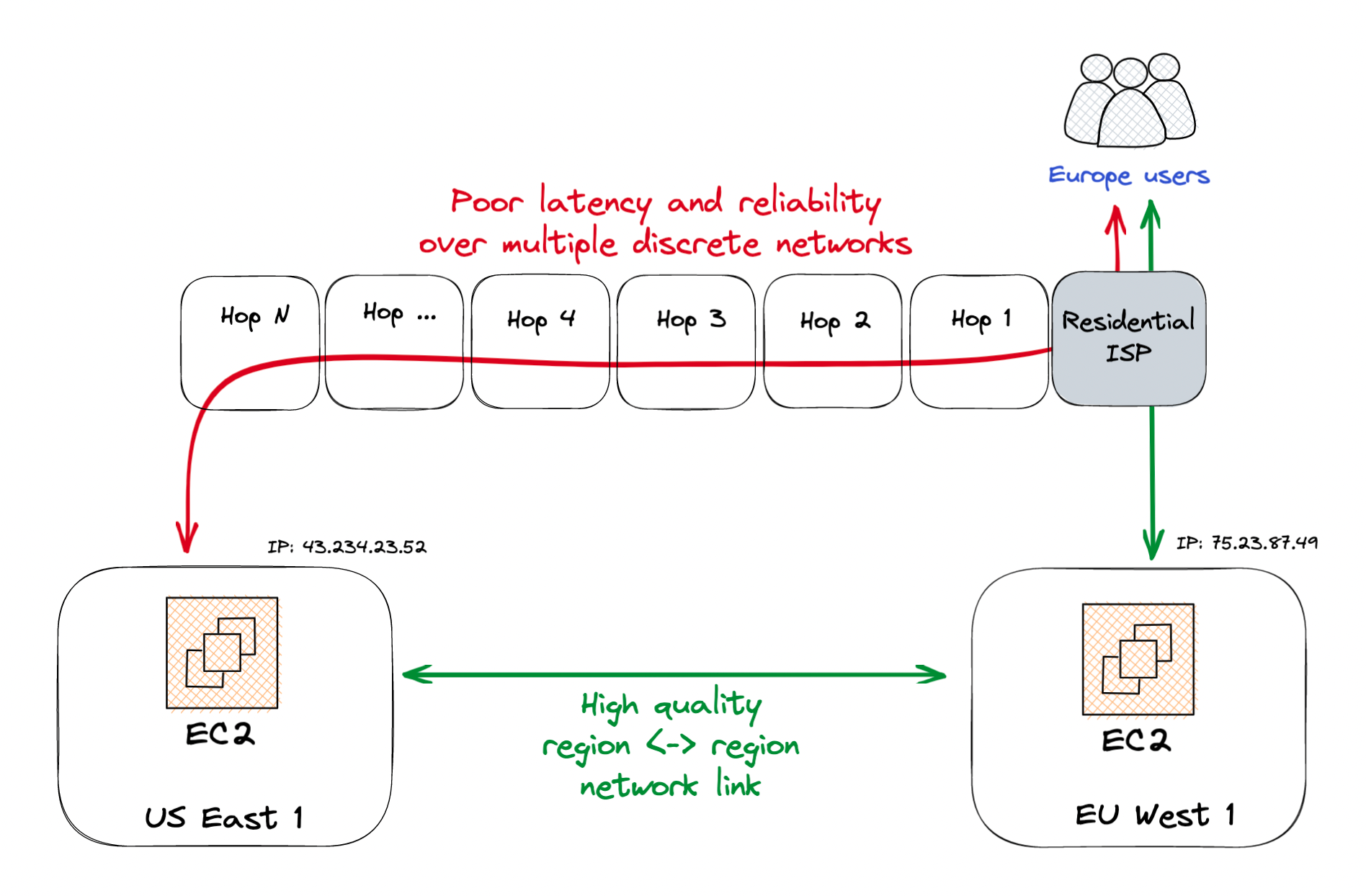
To troubleshoot this issue, Alice begins to read about how the Internet gets a packet from point A to point B. She realizes that occasional lag spikes are likely due to suboptimal paths these packets can take – especially if a residential ISP is communicating with a server far away. Residential ISPs usually optimize on cost, which means they don't have priority bandwidth on downstream links and often pick longer paths to save money.
The reason that players are experiencing occasional lag when connecting to a server outside their region is that their network packets may have to jump through 10+ intermediary nodes. On the other hand, data center to data center links offer much more control over routing and can often route packets in a single hop.
Alice modifies her architecture so that users only connect to server closest to them (using geo-location DNS). That edge server will be responsible for finding the server that's hosting the room that the user is trying to connect to, and if it's a server in another region, proxying traffic between the two regions.
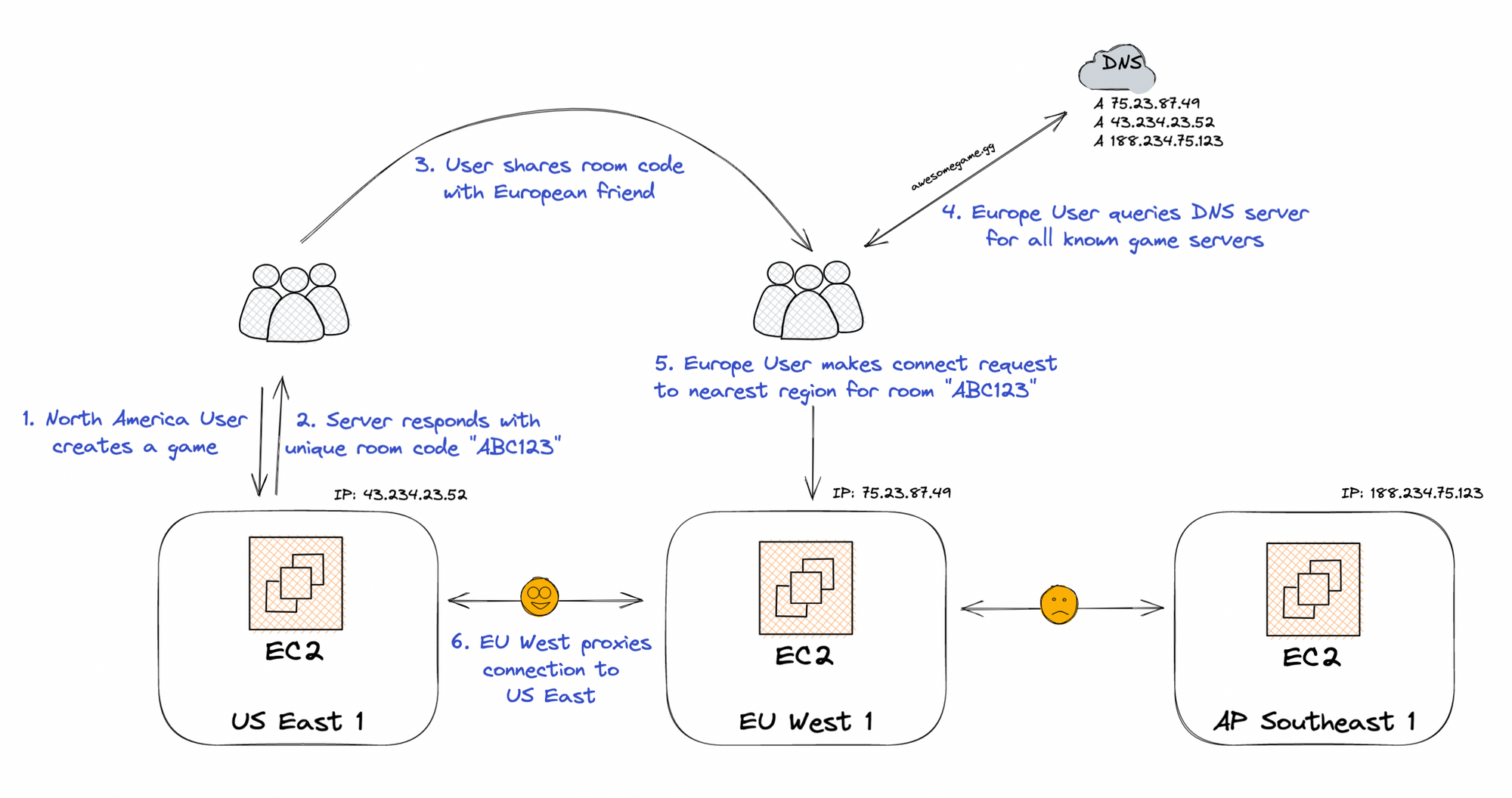
Alice explains to Bob the main advantage with this approach is the connection between the European player and the US East server first goes to the EU West server and then traverses the Atlantic Ocean on extremely high quality links between the two data centers. Previously, European users were directly connecting to the US data center, which meant letting their ISP determine the route they took across the Atlantic. Even the best of ISPs will find it difficult to beat the performance and reliability of a dedicated connection between data centers in two regions.
Riot Games published an in-depth article describing the challenges of routing users over links that prioritize latency over cost or throughput. After Riot moved over to their private network, the percentage of League of Legends players who had a sub-80ms ping jumped from 30% to 85%!
After rearchitecting the client and server to fit this model, Alice happily reports to Bob that their edge network is in place. They notice an immediate drop in the latency distribution of users connected. Now that global users have a smoother experience, there is a sizable uptick in players in regions that previously had no coverage. Their game is on the way to becoming a big hit!
Alice spent 20+ weeks on getting the infrastructure right – time that could have been spent creating new experiences for her users. Like Alice and Bob, many game developers go through a journey of tuning their game’s server infrastructure, with various struggles and triumphs along the way. Some are still hosting their game from their desktop at home, while others have managed to make their infrastructure multi-region.
As daunting as Alice and Bob’s journey may seem, the truth is that this article only scratches the surface of what it takes to run gaming infra like the pros do it. To give you an idea, we haven’t even talked about various concepts that become critical to get right at scale:
- Auto-scaling – how to automatically spin up new server instances when player load spikes, and spin them down to reduce cost when the load subsides
- Failover – how to handle expected failure (server upgrades) and unexpected failure (VM goes down) while minimizing disruption to gameplay
- Analytics – how to gain insight into player activity: Who is playing? Where are they playing from? How long are they playing? Are they running into errors?
- Persistence – how to store game and player data in a way such that it persists reliably and consistently across regions
The largest studios have spent thousands of man-hours developing in-house solutions to some of these problems. This has simply been out of reach for everyone else.
Hathora Cloud
At Hathora, we believe that all game developers should have access to this functionality. That’s why we’ve built Hathora Cloud, the most advanced gaming infrastructure solution available to the general public. The Hathora team brings decades of infrastructure SaaS and distributed systems experience at some of the largest cloud deployments, and we're super excited to apply those learnings to modernize the multiplayer stack.
Hathora Cloud provides a one-command deploy experience:
> hathora cloud deploy --appName my-awesome-game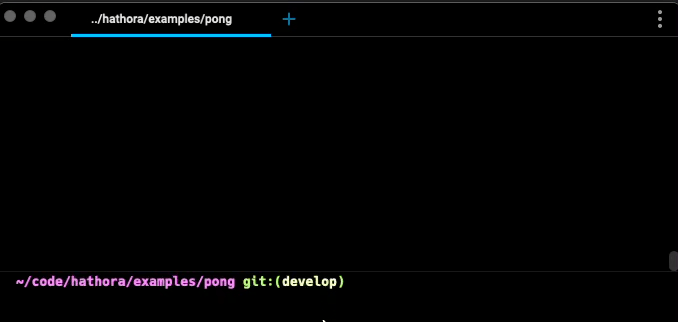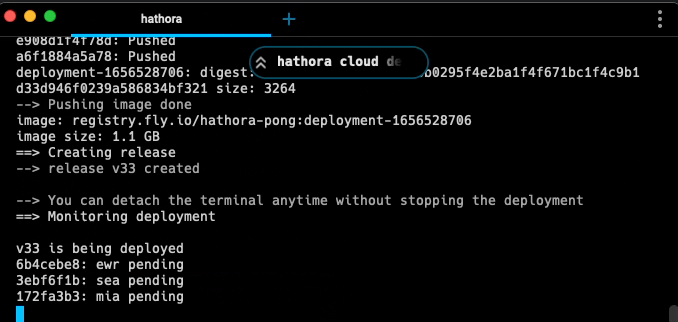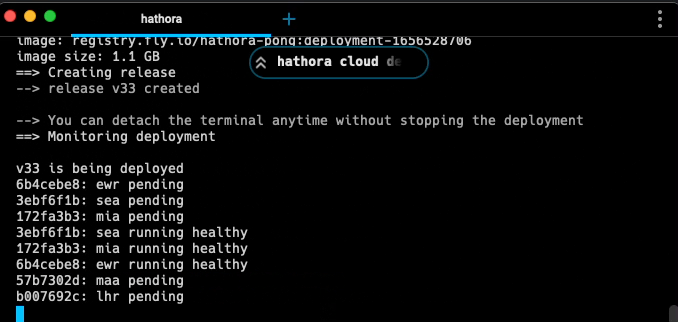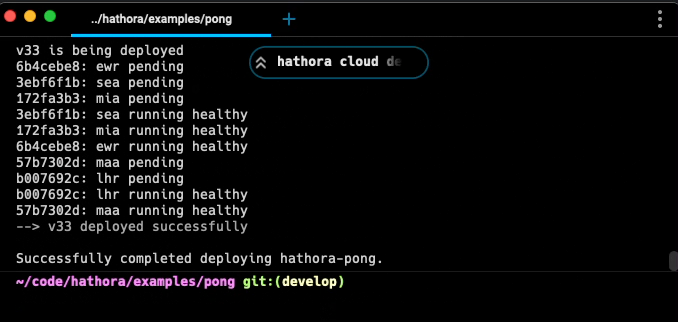
By running this single command, you've solved the challenges described in this article and more:
- Built your application code into a reproducible Docker container
- Published this artifact into a Docker registry
- Scheduled compute for your game globally across several regions
- Enabled secure client connections via multiple transport options: WebSocket, TCP, UDP
- Created optimized routes for your user traffic that enters at the edge node closest to them
- Set up auto-scaling, transparent failover, and analytics
Further, we are taking an unprecedented step and making all of this available on our free development tier. Until now, cost has been a prohibitive factor for an indie dev or small studio to achieve this level of infrastructure maturity, but with Hathora Cloud this technology is available to all.
Hathora Cloud handles your infrastructure challenges so that you can focus on creating great multiplayer experiences for your users.
Hathora Cloud has been incubating with select design partners and is now opening up to a broader public beta. If you're interested in deploying your game on a modern cloud designed for gaming, please sign up to get added to the beta!

